Nuttx - Memory Management
用户态的
malloc(100)在 KERNEL 模式下经历了什么?本文从用户堆管理往下追踪,穿过 kmm_malloc → pgalloc → L2 页表写入,拆解四层内存分配器如何协作——每一层的算法、数据结构和临界区。
本文回答以下问题:用户进程调用 malloc() 时,内存从哪里来?堆空间不够时如何动态扩展?物理页是怎样被分配并映射到用户虚拟地址的?内核堆和用户堆有什么区别?读完后,你将能够从源码级别追踪一次 malloc() 从用户空间穿透到 MMU 页表的完整路径,并理解 NuttX 四层分配器各自的职责与边界。
1. 开篇:KERNEL 模式下内存管理要解决什么问题?
在 FLAT 模式下,所有任务共享一个全局堆——malloc() 直接从这个堆中分配,简单直接。但在 KERNEL 模式下,每个用户进程拥有独立的虚拟地址空间,这引入了三个 FLAT 模式不存在的问题:
- 隔离:进程 A 的堆内存不能被进程 B 访问,需要 MMU 页表保证
- 映射:用户虚拟地址必须映射到物理页才能使用,但物理页的分配和映射是内核特权操作
- 扩展:用户堆初始只有很小的空间,
malloc()超出时需要动态申请新物理页并更新页表
这三个问题导致 KERNEL 模式需要一个多层分配器架构——用户态的 malloc() 最终要穿透多层才能拿到可用内存。
NuttX 官方文档 Documentation/implementation/memory_configurations.rst(第 508-537 行)对此有明确描述:物理页分配器(page allocator)是 KERNEL 模式下 malloc() 的底层支撑,用户堆通过 sbrk() 接口按需扩展。本文将沿着这条路径逐层深入。
接下来先看 qemu-armv7a 上的物理内存布局,这是所有分配器的”原材料”。
2. 物理内存布局(qemu-armv7a)
所有虚拟地址最终映射到物理内存。理解物理内存的分区方式,才能理解各层分配器的”地盘”在哪里。
2.1 qemu-armv7a 内存映射
1 | Physical Address Usage Size |
三个关键区域:
| 区域 | 作用 | 分配器 |
|---|---|---|
| Kernel Heap | 内核数据结构(TCB、task_group、内核栈等) | kmm_malloc() |
| Page Pool | 用户进程的物理页(.text、.data、heap、stack、L2 页表) | mm_pgalloc() |
| Kernel L1 Page Table | 所有进程 L1 页表的模板 | 固定,不分配 |
Page Pool 是用户进程物理内存的唯一来源——所有用户 .text、.data、堆页、栈页,以及 L2 页表本身,都从这里分配。
有了物理布局的全貌,下面看 NuttX 如何用四层分配器将物理页面转化为用户可用的虚拟内存。
3. 四层分配器架构总览
单层分配器无法同时满足:字节级精细分配(用户 malloc 16 字节)、页级物理内存管理(4KB 粒度)、MMU 映射操作(写 L2 页表)。NuttX 将这些职责分层,每层只关注一个粒度:
1 | Layer 4 (top) malloc(size) / free(ptr) User API |
| 层 | 组件 | 粒度 | 关键文件 |
|---|---|---|---|
| 4 | malloc()/free() |
字节 | mm/umm_heap/umm_malloc.c |
| 3 | mm_malloc()/mm_free() |
块(chunk) | mm/mm_heap/mm_malloc.c |
| 2 | sbrk() → pgalloc() |
页(4KB) | mm/umm_heap/umm_sbrk.c, arch/arm/src/armv7-a/arm_pgalloc.c |
| 1 | mm_pgalloc() → gran_alloc() |
页(4KB) | mm/mm_gran/mm_pgalloc.c, mm/mm_gran/mm_granalloc.c |
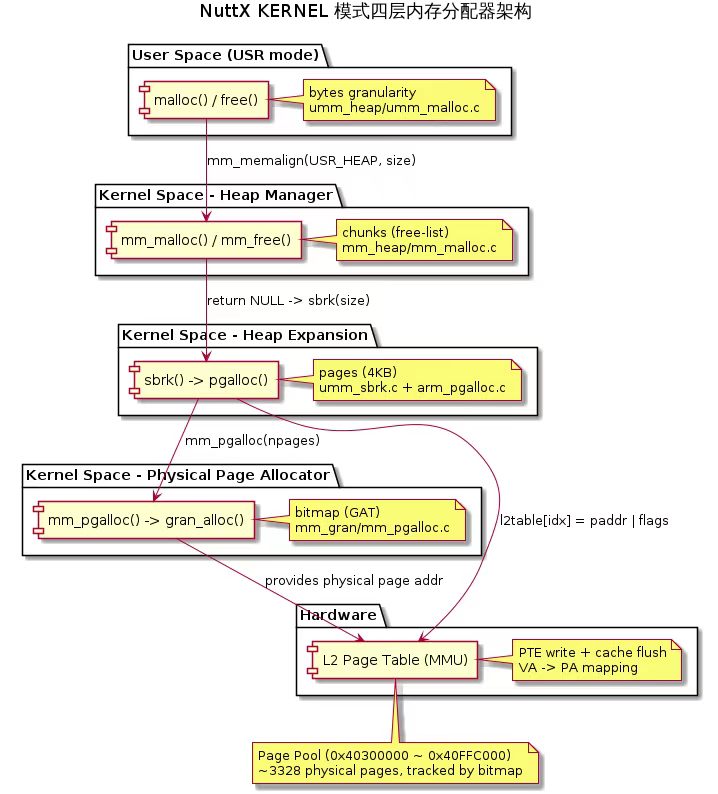
实例:malloc(100) 穿透四层的具体地址
1 | Layer 4: malloc(100) 由用户进程在 VA 0x80201008 处获得 100 字节 |
接下来从底层往上逐层剖析。先从最底层的物理页分配器开始——因为上层最终都依赖它。
4. Layer 1:物理页分配器(mm_pgalloc + 粒度分配器)
用户进程的每个虚拟页(4KB)背后必须有一个物理页支撑。当用户堆扩展、新进程加载 ELF 段、或分配用户栈时,都需要从 Page Pool 中分配物理页。物理页分配器的职责就是管理 Page Pool 中哪些页是空闲的、哪些已被使用。
4.1 初始化:mm_pginitialize()
文件:mm/mm_gran/mm_pgalloc.c:99-103
1 | void mm_pginitialize(FAR void *heap_start, size_t heap_size) |
在 nx_start() 启动时调用:up_allocate_pgheap(&start, &size) 获取 Page Pool 的物理地址和大小,然后 mm_pginitialize() 初始化粒度分配器。MM_PGSHIFT = 12(即 4KB = 2^12),粒度和对齐都是一个页。
4.2 分配:mm_pgalloc()
文件:mm/mm_gran/mm_pgalloc.c:148-151
1 | uintptr_t mm_pgalloc(unsigned int npages) |
返回值是物理地址——这块内存还没有被映射到任何虚拟地址,不能直接使用。调用者(pgalloc())负责将其映射到用户虚拟地址空间。
4.3 粒度分配器的 bitmap 算法
文件:mm/mm_gran/mm_gran.h:68-81
1 | struct gran_s |
GAT(Granule Allocation Table) 是一个位图,每个 bit 对应一个 4KB 页:
1 | Page Pool: 13MB ÷ 4KB = 3328 pages → 3328 bits → 104 个 uint32_t |
实例:分配 1 页的过程
1 | gran_alloc(g_pgalloc, 4096): |
对比 Linux buddy system:Linux 使用 buddy allocator(O(1) 分配、支持多种 order),而 NuttX 用线性扫描位图(O(n) 最坏情况)。为什么?因为嵌入式系统的 Page Pool 通常很小(几千页),线性扫描足够快,且位图实现极简、内存开销最低(每页仅 1 bit)。
物理页分配器解决了”从哪里拿物理页”的问题。下一步是把这些物理页映射到用户虚拟地址——这是 Layer 2 的职责。
5. Layer 2:堆扩展(sbrk → pgalloc → L2 页表)
用户堆初始只有很小的空间(甚至可能是 0)。当 mm_malloc() 发现空闲链表中没有足够大的块时,它需要向操作系统请求更多内存。在 Unix/Linux 中这是 sbrk() 或 mmap() 的职责。NuttX KERNEL 模式实现了 sbrk()。
5.1 sbrk() 实现
文件:mm/umm_heap/umm_sbrk.c:76-126
1 | FAR void *sbrk(intptr_t incr) |
sbrk() 做三件事:
- 计算需要多少页:
MM_NPAGES(incr)将字节数向上取整到页数 - **调用
pgalloc()**:分配物理页 + 映射到虚拟地址 - **调用
mm_extend()**:告诉堆管理器”你有更多空间可用了”
5.2 pgalloc():物理页分配 + MMU 映射的桥梁
文件:arch/arm/src/armv7-a/arm_pgalloc.c:178-254(以下为关键路径摘录并添加 Step 注释标注,原函数含调试日志和断言共 76 行)
这是 KERNEL 模式内存管理的核心函数——它将 Layer 1(物理页分配)和 MMU 映射连接起来:
1 | uintptr_t pgalloc(uintptr_t brkaddr, unsigned int npages) |
实例:用户堆从 0x80200000 扩展一页到 0x80201000
1 | pgalloc(0x80200000, 1): |
此后,用户进程访问 VA 0x80200000-0x80200FFF 时,MMU 会通过 L1→L2 查表,找到物理页 0x40321000 上的数据。
pgalloc() 是 Layer 2 的核心。它上面是堆管理器(Layer 3),下面是物理页分配器(Layer 1)。下一节看堆管理器如何管理已映射的虚拟内存。
6. Layer 3:核心堆管理器(mm_heap)
pgalloc() 以页(4KB)为粒度。但用户可能只需要 16 字节。堆管理器的职责是在已映射的虚拟页内做字节级细分——将 4KB 页切割为多个小块,按需分配给用户,并在释放时合并回大块。
6.1 核心算法原理(选读)
mm_heap 的算法可以用三个关键词概括:块(chunk)、桶(bucket)、合并/分裂(coalesce/split)。
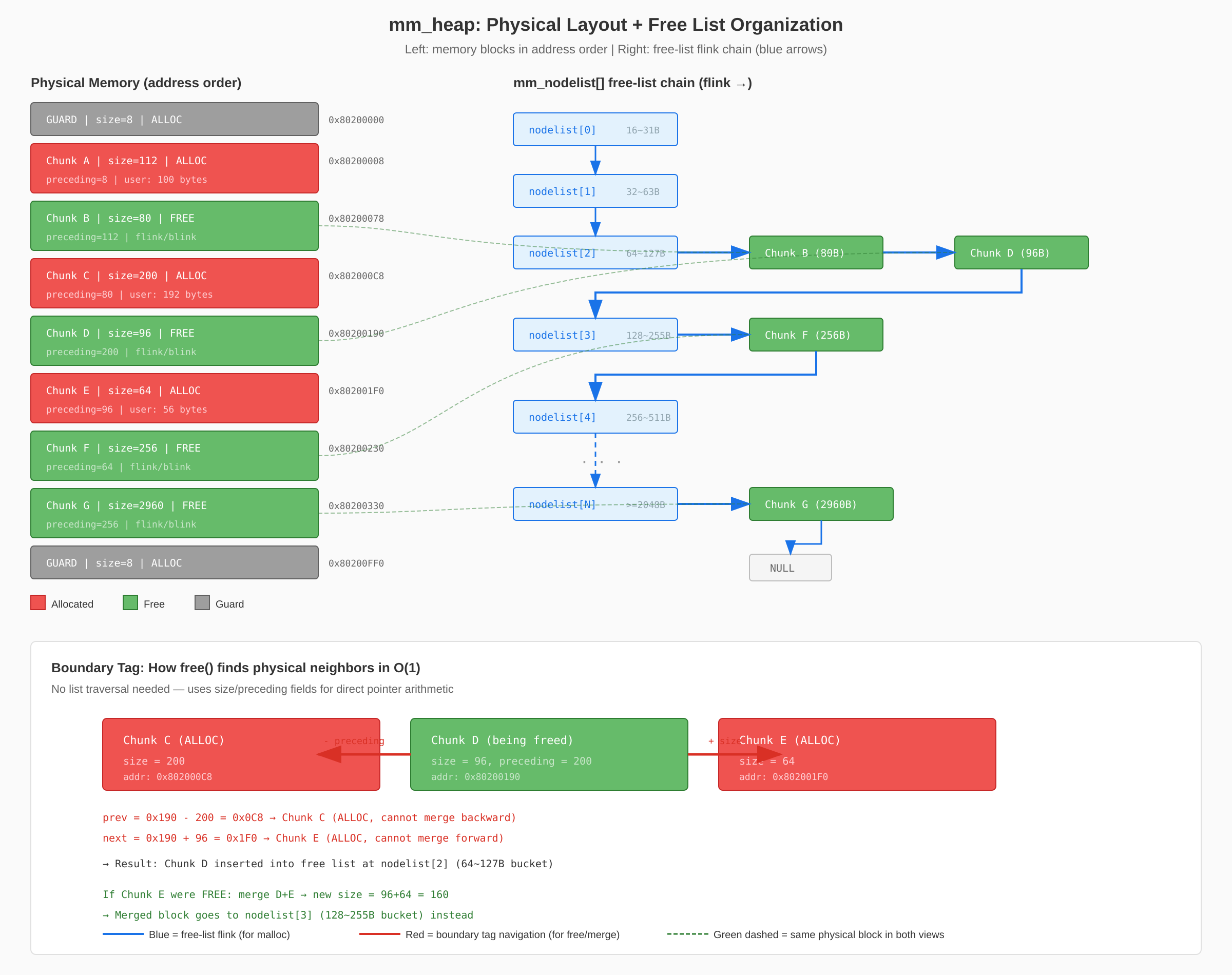
原理一:整块内存被切成”块”,每块前面贴个标签
堆就是一段连续内存,被切成大小不等的块。每块开头有一个 8 字节的 header,记录本块大小和分配状态。已分配块的用户数据紧跟在 header 后面;空闲块的 header 之后是链表指针(flink/blink),用于串入空闲链表。
1 | Heap memory (one contiguous region): |
原理二:空闲块按大小分桶索引
空闲块按大小分散到多个”桶”中,但所有桶串在同一条双向链表上——mm_nodelist[] 的每个元素是链表中的哨兵节点(size=0),真正的空闲块穿插在哨兵之间,整体按大小升序排列:
1 | nodelist[0] <-> [16B] <-> [24B] <-> nodelist[1] <-> [32B] <-> [48B] <-> nodelist[2] <-> [80B] <-> ... |
malloc(100) 时,计算 alignsize = 112,定位到桶 3(>= 128B),从 nodelist[3].flink 开始遍历。如果桶 3 为空,循环自动穿过下一个哨兵进入更大的桶——无需额外跳桶逻辑。找到第一个 >= 112 的块就是 best-fit。
原理三:分裂与合并
- 分裂(split):找到的空闲块太大时(比如要 112B 但找到 256B),切成两半——前半给用户,后半作为新空闲块放回对应桶。
- 合并(coalesce):释放时检查物理相邻的前后块是否也是空闲的,如果是就合并成一个更大的空闲块,放入更大的桶。这减少了碎片。
关键问题:空闲链表按大小排序,怎么找到物理相邻的块?
答案是:不通过空闲链表找邻居。每个块的 header 中有 size(本块大小)和 preceding(前一块大小)两个字段,构成”边界标签(boundary tag)”。通过指针算术 O(1) 直接跳到物理邻居:
1 | preceding size preceding size preceding size |
所以合并时:
- 后邻居:
next = (char *)node + node->size— 直接算出地址 - 前邻居:
prev = (char *)node - node->preceding— 直接算出地址 - 检查邻居是否空闲:看
next->size的MM_ALLOC_BIT,或本块size的MM_PREVFREE_BIT
空闲链表和物理邻居各管各的事:
| 机制 | 用途 | 寻址方式 |
|---|---|---|
flink/blink 空闲链表 |
malloc 时找可用块 | 按大小遍历 |
size/preceding 边界标签 |
free 时找物理邻居做合并 | 指针算术(O(1)) |
与 FreeRTOS heap_4 的关系:底层的块管理(header、边界标签、合并、分裂)思路一致,NuttX 在此基础上加了分桶索引和 best-fit 策略,提升了搜索效率和碎片控制。
理解了这三个原理,下面看具体的数据结构如何支撑它们。
6.2 数据结构
文件:mm/mm_heap/mm.h:175-205
1 | /* 已分配块的头部(每个分配的内存块前面都有这个) */ |
size 字段的低 2 位被复用为标志(文件:mm/mm_heap/mm.h:128-130):
1 |
堆本身的结构(文件:mm/mm_heap/mm.h:221-277):
1 | struct mm_heap_s |
6.3 分桶空闲链表
mm_nodelist[] 看起来是一个数组,但实际上所有桶串在同一条双向链表上。mm_nodelist[0] ~ mm_nodelist[N] 本身是链表中的哨兵节点(size=0),真正的空闲块按大小升序穿插其间:
1 | mm_nodelist[0] <-> [16B] <-> [24B] <-> mm_nodelist[1] <-> [32B] <-> [48B] <-> mm_nodelist[2] <-> [80B] <-> ... -> NULL |
桶的划分基于 2 的幂次:
1 | mm_nodelist[0]: 16~31B 的空闲块在这个哨兵之后 |
这个设计的巧妙之处:malloc() 从 mm_nodelist[ndx].flink 开始遍历,如果当前桶没有够大的块,循环会穿过下一个哨兵(size=0,不满足条件,跳过)自动进入更大的桶继续搜索——无需额外的”找下一个桶”逻辑。
下图展示了堆的物理内存布局(左)和空闲链表组织(右)的对应关系,以及边界标签导航(底部):
6.4 mm_malloc() 算法
文件:mm/mm_heap/mm_malloc.c:170-413(以下为核心逻辑摘录,原函数含锁处理、mempool 快路径等共 243 行)
1 | FAR void *mm_malloc(FAR struct mm_heap_s *heap, size_t size) |
实例:malloc(100) 的内部过程
1 | (1) alignsize = ALIGN_UP(100 + 8) = ALIGN_UP(108) = 112 bytes (8字节对齐) |
6.5 mm_free() 算法:合并相邻空闲块
文件:mm/mm_heap/mm_free.c:84-221
释放时尝试与物理相邻的前后空闲块合并,减少碎片:
1 | void mm_delayfree(FAR struct mm_heap_s *heap, FAR void *mem, bool delay) |
合并使得释放的内存可以被后续更大的分配重用,避免出现大量无法使用的小碎片。
堆管理器负责虚拟内存内的字节级分配。当它空间不足时,会调用上面的 sbrk() 扩展。接下来看上层的用户堆和内核堆如何使用这个核心管理器。
7. Layer 4:用户堆与内核堆
- 内核堆(kmm):内核代码分配 TCB、task_group、内核栈、驱动缓冲区等。位于内核地址空间(恒等映射的 DDR),所有进程可见。
- 用户堆(umm):每个用户进程自己的
malloc()。位于用户虚拟地址空间(0x80200000+),进程间隔离。
7.1 内核堆初始化
文件:mm/kmm_heap/kmm_initialize.c:61-70
1 | void kmm_initialize(FAR void *heap_start, size_t heap_size) |
在 nx_start() 中被调用:up_allocate_kheap() 确定内核堆的起止范围(从 g_idle_topstack 到 Page Pool 起始之前),然后 kmm_initialize() 创建堆。
kmm_malloc(size) 就是 mm_malloc(g_kmmheap, size) 的简单包装——不涉及页分配或 MMU 操作,因为内核堆的虚拟地址就是物理地址(恒等映射)。
7.2 用户堆初始化
文件:mm/umm_heap/umm_initialize.c:87-100
1 | void umm_initialize(FAR void *heap_start, size_t heap_size) |
USR_HEAP 的解析(文件:include/nuttx/mm/mm.h:119):
1 |
在 KERNEL 模式下,USR_HEAP 指向进程 .data 段开头保留区域中的堆指针。每个进程有自己的 .data 段(映射到不同物理页),所以每个进程有自己的 USR_HEAP。
7.3 惰性初始化:umm_try_initialize()
文件:mm/umm_heap/umm_initialize.c:117-146
1 | void umm_try_initialize(void) |
用户进程首次 malloc() 时触发:分配第一个物理页映射到 CONFIG_ARCH_HEAP_VBASE(0x80200000),在上面初始化 mm_heap_s 结构。之后的 malloc() 就在这个堆上分配,空间不够时 sbrk() 继续扩展。
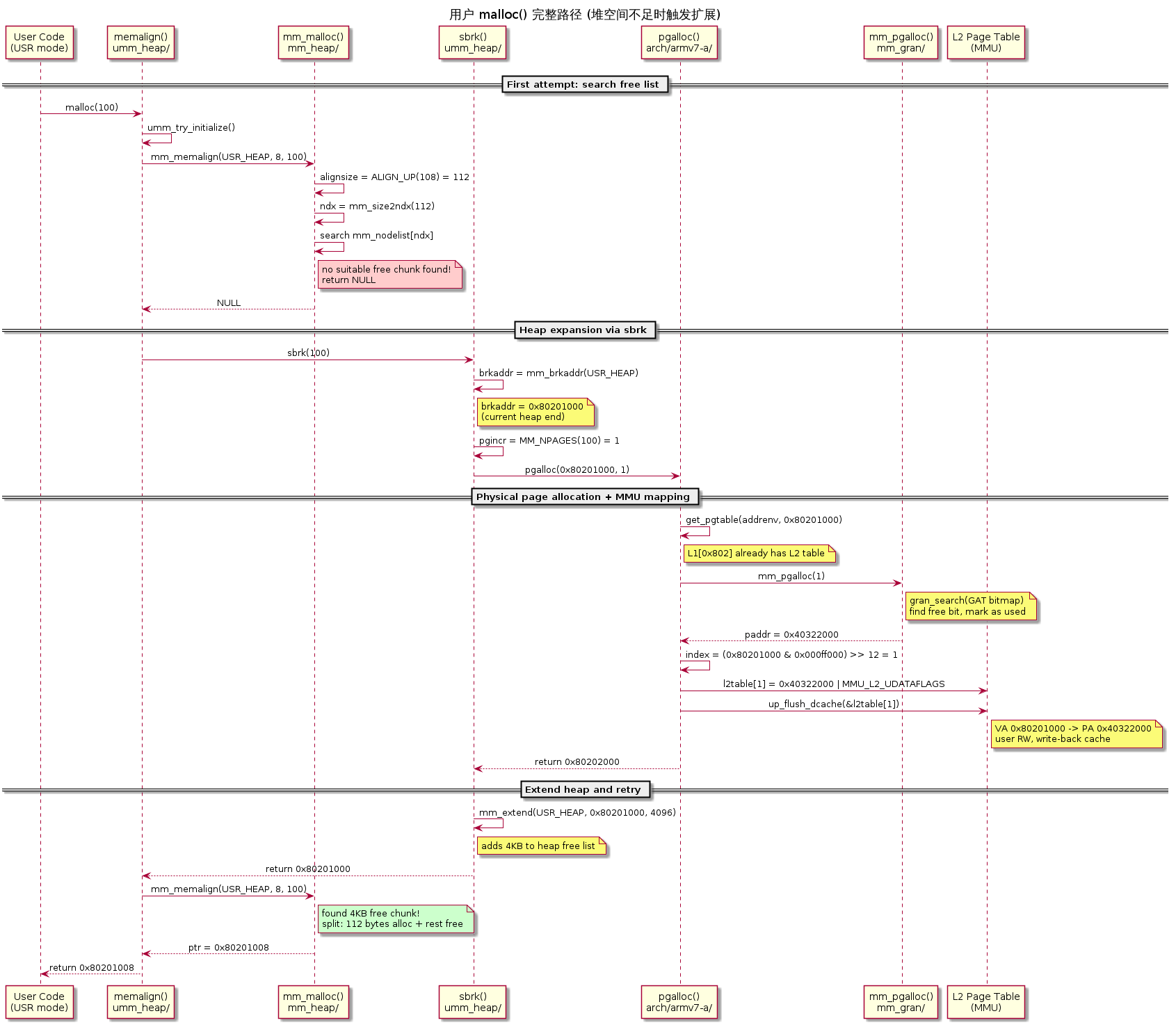
7.4 malloc() 到 sbrk() 的触发路径
文件:mm/umm_heap/umm_memalign.c:54(KERNEL 模式下 malloc() 实际调用 memalign())
当 mm_malloc() 返回 NULL 时:
1 | FAR void *memalign(size_t alignment, size_t size) |
整个链条:malloc(100) → memalign(8, 100) → mm_memalign() 返回 NULL → sbrk(100) → pgalloc() 分配物理页 + 映射 → mm_extend() 扩展堆 → 重试 mm_memalign() 成功。
下图展示了堆空间不足时 malloc() 触发扩展的完整时序:
8. 内存释放与进程退出
分配只是内存管理的一半。如果释放逻辑有缺陷(碎片化、无法合并、泄漏),长时间运行的嵌入式系统会逐渐耗尽内存。此外,KERNEL 模式下进程退出时的”批量回收”机制是其相比 FLAT 模式的重要优势——理解它才能明白为什么 KERNEL 模式不怕用户进程的内存泄漏。
8.1 free() 路径
1 | free(ptr) |
释放的内存回到空闲链表,可被后续 malloc() 重用。注意:释放不会归还物理页给 Page Pool——已映射的页永远属于该进程的堆,直到进程退出。
8.2 延迟释放(mm_delaylist)
文件:mm/mm_heap/mm_free.c:84-100
如果 free() 时无法获取堆的 mutex(例如在中断上下文中被调用),内存块被放入 per-CPU 的 mm_delaylist[],等下次 malloc() 时批量处理:
1 | if (mm_lock(heap) < 0 || delay) |
8.3 进程退出时的整体回收
当进程的最后一个线程退出时,整个地址环境被销毁:
1 | addrenv_destroy() |
进程退出时不需要逐个 free() 堆上的对象——整个地址空间的物理页被批量归还给 Page Pool。这比 FLAT 模式(需要手动 free 每个分配)高效得多。
9. 对比分析
| 特性 | NuttX KERNEL | NuttX FLAT | Linux |
|---|---|---|---|
| 堆的数量 | 每进程一个用户堆 + 一个内核堆 | 全局一个堆 | 每进程用户堆 + SLAB/SLUB 内核堆 |
| 物理页分配器 | 粒度位图(线性扫描) | 无 | Buddy system(O(1)) |
| 堆扩展机制 | sbrk() → pgalloc() |
无(堆大小固定) | brk()/mmap() → page fault → alloc |
| 用户 malloc 失败时 | 同步扩展(sbrk 立即分配页) |
直接返回 NULL | lazy(先映射虚拟,访问时 page fault) |
| 进程退出时 | 批量归还物理页 | 需手动 free(否则泄漏) | 销毁地址空间,批量归还 |
| 空闲块管理 | 分桶空闲链表(best-fit) | 同 | SLAB(small)+ Buddy(large) |
| 碎片处理 | 前后合并 | 同 | SLAB + compaction |
| 内存开销/块 | 8 字节 header | 同 | SLAB 无 header(基于 page offset) |
NuttX 的设计取舍:
- 用同步分配而非 Linux 的 demand paging——简化了实现(不需要 page fault handler),代价是
malloc()可能阻塞较长时间 - 用位图而非 buddy——节省内存(Page Pool 几千页只需几百字节位图),代价是分配速度 O(n)
- 用分桶链表而非 SLAB——通用性好(适合各种大小),代价是小对象有 8 字节 header 开销
10. 关键要点
NuttX KERNEL 模式使用四层分配器:用户 API(malloc)→ 核心堆管理器(mm_malloc)→ 堆扩展(sbrk/pgalloc)→ 物理页分配器(granule bitmap)。
内核堆和用户堆完全独立:内核堆在恒等映射的 DDR 上,无需 MMU 操作;用户堆在进程独有的虚拟地址空间,每次扩展需要分配物理页 + 写 L2 PTE。
pgalloc()是 KERNEL 模式的核心桥梁:它将 Layer 1(物理页)和 MMU 映射连接起来,每次调用做 3 件事:确保 L2 页表存在、分配数据页、写 PTE + flush cache。物理页分配使用 bitmap 算法:Page Pool 中每页用 1 bit 跟踪,
gran_alloc()线性扫描找连续空闲位。简单但对嵌入式场景足够。用户堆惰性初始化:首次
malloc()时才分配第一个页并创建堆结构,避免为从不使用堆的进程浪费物理页。free()不归还物理页:释放的内存回到堆空闲链表供重用,但物理页不会还给 Page Pool。只有进程退出时才批量回收。进程退出 = 批量回收:
addrenv_destroy()遍历所有 L2 页表条目,将所有物理页和页表页归还 Page Pool。不需要逐个 free。
11. 参考文件索引
| 文件路径 | 关键内容 | 引用行号 |
|---|---|---|
mm/mm_heap/mm.h |
mm_allocnode_s, mm_freenode_s, mm_heap_s | 68-277 |
mm/mm_heap/mm_malloc.c |
mm_malloc() 核心算法 | 170-413 |
mm/mm_heap/mm_free.c |
mm_delayfree() 释放与合并 | 84-221 |
mm/mm_heap/mm_initialize.c |
mm_addregion() 堆初始化 | 234+ |
mm/mm_heap/mm_extend.c |
mm_extend() 堆扩展 | 54+ |
mm/kmm_heap/kmm_initialize.c |
kmm_initialize() 内核堆 | 61-70 |
mm/umm_heap/umm_initialize.c |
umm_initialize(), umm_try_initialize() | 87-146 |
mm/umm_heap/umm_sbrk.c |
sbrk() 实现 | 76-126 |
mm/umm_heap/umm_memalign.c |
memalign() 触发 sbrk | 54+ |
mm/mm_gran/mm_gran.h |
struct gran_s 粒度分配器 | 68-81 |
mm/mm_gran/mm_pgalloc.c |
mm_pgalloc(), mm_pginitialize() | 99-197 |
mm/mm_gran/mm_granalloc.c |
gran_alloc() 位图搜索 | 43+ |
mm/mm_gran/mm_grantable.c |
gran_search(), gran_set() | 260-299 |
arch/arm/src/armv7-a/arm_pgalloc.c |
pgalloc() MMU 映射 | 178-254 |
arch/arm/src/armv7-a/arm_addrenv.c |
up_addrenv_create/destroy | 167-314 |
arch/arm/src/armv7-a/arm_addrenv_utils.c |
arm_addrenv_create/destroy_region | 60-214 |
include/nuttx/mm/mm.h |
USR_HEAP 宏定义 | 119 |
include/nuttx/addrenv.h |
addrenv_reserve_s (ar_usrheap) | 301-305 |
sched/init/nx_start.c |
启动时初始化 kmm + pgalloc | 540-575 |
sched/addrenv/addrenv.c |
addrenv_destroy() 进程退出回收 | 196+ |
arch/arm/src/armv7-a/arm_allocateheap.c |
up_allocate_kheap(), up_allocate_pgheap() | 241+ |
Documentation/implementation/memory_configurations.rst |
官方内存配置文档 | 508-537 |