Nuttx - Task Scheduling
NuttX 怎么做到”每个进程有独立地址空间”?用户态函数调用怎么穿过 SVC 陷阱进入内核?高优先级任务就绪后,调度器如何当场抢走 CPU?本文基于 ARMv7-A MMU,从地址环境、系统调用陷入、双栈切换到优先级继承,完整拆解 KERNEL 模式下的任务生命周期。
本文回答以下问题:NuttX KERNEL 模式下进程和线程的本质区别是什么?每个进程的独立地址空间在硬件层面如何实现(L1/L2 页表)?用户进程如何通过系统调用安全地访问内核服务?调度器在切换进程时如何同时完成寄存器保存和地址空间切换?
读完后,你将能够从源码级别理解 armv7a-qemu 上一个用户进程从 ELF 加载到获得 CPU 的完整路径,并具备独立分析调度延迟、syscall 开销和地址空间故障的能力。
1. 开篇:为什么需要 KERNEL 构建模式?
在资源受限的 MCU 上,NuttX 通常以 FLAT 模式运行——所有任务共享同一地址空间,任何任务的野指针都可能破坏整个系统。这对安全性要求高的场景(航空电子、医疗设备、汽车 ECU)是不可接受的。
KERNEL 构建模式(CONFIG_BUILD_KERNEL)利用 ARMv7-A 的 MMU(Memory Management Unit)实现:
- 进程地址空间隔离:每个用户进程拥有独立的虚拟地址空间(独立的 L1 页表)
- 特权级分离:用户代码运行在 USR 模式(无法访问内核内存),内核代码运行在 SYS/SVC 模式
- 系统调用边界:用户进程只能通过 SVC 指令陷入内核,访问受控的 API
NuttX 官方文档(Documentation/implementation/processes_vs_tasks.rst)描述:
“The kernel build, selected with CONFIG_BUILD_KERNEL, uses the MCU’s Memory Management Unit (MMU) to implement processes very similar to Linux processes.”
本文基于 ARMv7-A 架构,完整剖析 KERNEL 模式下的:
- 进程模型——Task/Pthread/Kthread 在 KERNEL 模式下的本质区别
- 地址环境——每进程 L1 页表的创建、切换与销毁
- 进程创建——从
posix_spawn()到 ELF 加载再到首次获得 CPU - 系统调用——SVC 陷入、Proxy/Stub 机制、内核栈切换
- 调度算法——优先级有序链表与抢占控制
- 上下文切换——寄存器保存 + TTBR0 页表切换的完整时序
- 时间片轮转与优先级继承
2. 进程模型:KERNEL 模式下的 Task、Pthread 与 Kthread
2.1 为什么 task_create() 在 KERNEL 模式下被禁用?
在 FLAT 模式下,task_create() 直接从内存中的函数指针启动新任务。但在 KERNEL 模式下,每个用户进程有自己的虚拟地址空间——父进程的函数地址在子进程中无意义。因此:
文件:sched/task/task_create.c:200
1 |
|
**KERNEL 模式下创建用户进程的唯一方式是 posix_spawn() / exec()**——通过 binfmt 层从文件系统加载 ELF 可执行文件,为其分配独立的地址空间。
2.2 三种线程类型的本质区别
| 特性 | 用户进程(User Task) | 用户线程(Pthread) | 内核线程(Kthread) |
|---|---|---|---|
| 创建方式 | posix_spawn() / exec() |
pthread_create() |
kthread_create() |
| 地址空间 | 独立 L1 页表 | 共享父进程 L1 页表 | 使用内核全局页表 |
| 运行模式 | USR 模式(非特权) | USR 模式(非特权) | SYS 模式(特权) |
| 内核栈 | 有(xcp.kstack) |
有 | 无(直接用分配的栈) |
| 用户栈 | 在用户地址空间 | 在用户地址空间 | 在内核地址空间 |
| task_group | 独立(新建) | 共享父进程的 | 共享 g_kthread_group |
addrenv_own |
指向独立 addrenv | 指向父进程 addrenv(引用计数+1) | NULL |
实例:系统中有一个用户进程 “myapp”(pid=3)和它创建的一个 pthread(pid=4)
1 | TCB(pid=3): flags=0x08 (TASK|SCHED_RR), addrenv_own=0x8F100000 (refs=2) |
pid=3 和 pid=4 共享同一个 addrenv_s,引用计数为 2。当其中一个退出,引用减到 1;最后一个退出时引用减到 0,触发地址环境销毁。
2.3 TCB 中的 KERNEL 模式关键字段
文件:include/nuttx/sched.h:593-598
1 |
|
文件:arch/arm/include/armv7-a/irq.h:328-331
1 | uint32_t *ustkptr; /* 保存的用户栈指针(syscall 进入时保存)*/ |
每个用户进程的 TCB 同时持有用户栈指针和内核栈指针——系统调用时从用户栈切到内核栈,返回时切回。
理解了进程模型后,下一个问题是:每个进程的”独立地址空间”在硬件层面如何实现?这就是地址环境的职责。
3. 地址环境(Address Environment):每进程页表架构
3.1 为什么需要每进程一份 L1 页表?
ARMv7-A 的 MMU 通过 TTBR0(Translation Table Base Register 0)寄存器指向当前进程的 L1 页表。切换进程就是切换 TTBR0 指向不同的 L1 页表——不同页表映射不同的物理页,从而实现地址空间隔离。
3.2 数据结构
文件:arch/arm/include/arch.h:134-159
1 | struct arch_addrenv_s |
文件:include/nuttx/addrenv.h:268-275
1 | struct addrenv_s |
实例:armv7a-qemu 上一个用户进程的地址环境字段值
1 | l1table = 0x40300000 (从 Page Pool 分配,16KB 对齐) |
3.3 虚拟地址空间布局(armv7a-qemu)
NuttX KERNEL 模式在 armv7a-qemu 上的实际内存布局如下。内核使用恒等映射(PA == VA,L1 section entries)占据低地址;用户空间使用纯虚拟映射(通过 L2 page table)占据高地址:
1 | Physical (PA == VA identity mapped) Virtual (VA only, per-process L2) |
关键设计要点:
- 内核区域(0x00000000-0x50000000)使用 L1 section entries(每条覆盖 1MB),PA == VA 恒等映射。无需 L2 页表,访问效率最高。
- 用户区域从 L1 index 0x800(VA 0x80000000)开始,使用 L2 coarse page table entries(每条覆盖 4KB)。不同进程映射到 Page Pool 中的不同物理页,实现地址隔离。
- Page Pool(DDR 中 0x40300000-0x40FFC000,约 13MB)是所有用户物理页的来源:L2 页表本身、用户 .text/.data、堆和栈页面都从这里分配。
- Kernel L1 Page Table 固定在 0x40FFC000(
PGTABLE_BASE_VADDR),是所有进程 L1 页表的”模板”——新进程的 L1 页表从这里memcpy而来。
实例:armv7a-qemu 上进程 “myapp” 的虚拟地址映射
1 | CONFIG_ARCH_TEXT_VBASE = 0x80000000 |
.text加载到 VA 0x80000000-0x8000FFFF(64KB ELF 代码,物理页来自 Page Pool).data加载到 VA 0x80100000-0x80103FFF(16KB,前 4KB 为 ARCH_DATA_RESERVE)- 用户堆从 VA 0x80200000 开始,初始 64KB,可通过
pgalloc()动态扩展 - 用户栈在 VA 0x80300000,默认 2048 bytes
3.4 地址环境创建:up_addrenv_create()
文件:arch/arm/src/armv7-a/arm_addrenv.c:167-256
1 | int up_addrenv_create(size_t textsize, size_t datasize, size_t heapsize, |
arm_addrenv_create_region()(文件:arch/arm/src/armv7-a/arm_addrenv_utils.c:60-151)对每个 1MB section:
- 分配一个物理页作为 L2 页表(256 entries x 4 bytes = 1KB,放在 4KB 页中)
- 将 L2 页表物理地址写入 L1 页表对应条目
- 为该 1MB 内的每个 4KB 页分配物理页
- 将物理页地址 + MMU flags 写入 L2 页表条目
3.5 地址环境切换:改写 TTBR0
文件:arch/arm/src/armv7-a/arm_addrenv.c:453-460
1 | int up_addrenv_select(const arch_addrenv_t *addrenv) |
文件:arch/arm/src/armv7-a/mmu.h:1408-1411
1 | static inline void mmu_l1_setpgtable(uintptr_t *ttb) |
整个地址空间切换就是两条 CP15 指令:写 TTBR0 + 无效化 TLB。之后所有用户态内存访问都通过新的 L1 页表翻译。
对比 Linux:Linux 在 ARMv7-A 上使用 ASID(Address Space ID)来避免每次切换都无效化整个 TLB。NuttX 当前不使用 ASID,每次切换都做完整的 TLB 无效化——对嵌入式场景(进程数少)可接受。
有了地址环境的基础设施,接下来看一个完整的用户进程是如何从 ELF 文件被加载、初始化并最终运行起来的。
4. 进程创建全流程:posix_spawn() 到首次运行
4.1 为什么进程创建比 FLAT 模式复杂得多?
在 KERNEL 模式下创建进程需要解决 FLAT 模式不存在的问题:
- 从 ELF 文件加载代码到新的虚拟地址空间中
- 在新地址空间中初始化用户堆
- 将 argv/envp 从父进程地址空间复制到内核堆(因为子进程无法访问父进程的用户内存)
- 分配双栈(用户栈在用户地址空间,内核栈在内核地址空间)
- 设置 TCB 使首次上下文切换后以 USR 模式运行
4.2 完整调用链
1 | posix_spawn(path, file_actions, attr, argv, envp) |
上述流程分为三个阶段:首先 ELF 加载器创建新的地址环境并将代码/数据写入新虚拟空间(此时临时切换 MMU);然后 exec_module() 在新地址空间中初始化用户堆、分配内核栈和用户栈;最后通过 nxtask_activate() 将新 TCB 放入就绪队列。整个过程中父进程的地址环境在每次临时切换后都会被恢复。
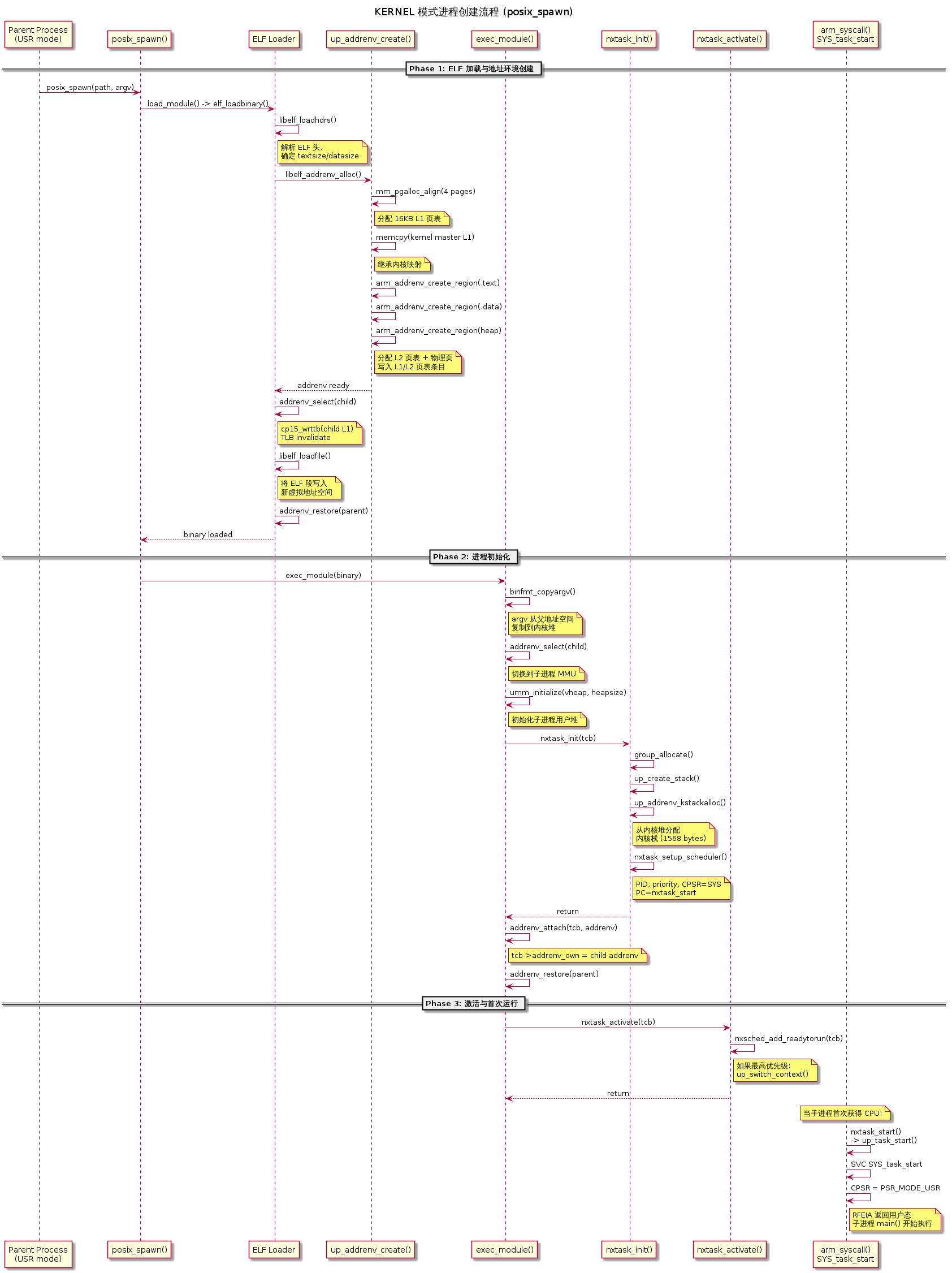
4.3 ELF 加载与地址环境分配
文件:libs/libc/elf/elf_addrenv.c:83-143(libelf_addrenv_alloc())
1 | /* Step 1: 分配 addrenv_s 结构(含引用计数)*/ |
之后 libelf_addrenv_select() 切换 MMU 到新地址空间,libelf_loadfile() 就可以直接用虚拟地址将 ELF 段内容写入新分配的物理页(因为 MMU 已经映射好了)。
4.4 用户堆初始化
文件:binfmt/binfmt_execmodule.c:213-241
1 | /* 切换到子进程地址空间 */ |
umm_initialize() 在子进程的虚拟堆地址处初始化堆管理结构。此时 MMU 指向子进程的 L1 页表,所以写入操作实际修改了子进程的物理堆页。
4.5 内核栈分配
文件:sched/task/task_init.c:167-178
1 |
|
文件:arch/arm/src/armv7-a/arm_addrenv_kstack.c:133-149
1 | int up_addrenv_kstackalloc(struct tcb_s *tcb) |
为什么用户进程需要内核栈? 源码注释(arm_addrenv_kstack.c:74-81)解释:
“When we instantiate and initialize the address environment of the new user process, we will temporarily lose the address environment of the old user process, including its stack contents. The kernel C logic will crash immediately with no valid stack in place.”
内核栈从 kmm_memalign() 分配,位于内核虚拟地址空间——该空间在所有进程的 L1 页表中共享映射,因此切换地址环境不会影响内核栈的可访问性。
4.6 首次运行:从内核态降级到用户态
当新进程首次被调度运行时,它从 nxtask_start() 开始(内核态):
文件:sched/task/task_start.c:97-107
1 | if (ttype == TCB_FLAG_TTYPE_KERNEL) |
文件:arch/arm/src/common/arm_task_start.c:67-74
1 | void up_task_start(main_t taskentry, int argc, char *argv[]) |
这触发 SVC,在 arm_syscall() 中处理(文件:arch/arm/src/armv7-a/arm_syscall.c:312-331):
1 | case SYS_task_start: |
当 SVC 异常返回(RFEIA)时,CPU 加载被修改的 CPSR——其中 mode 位已是 USR,于是 CPU 以非特权模式从用户入口点开始执行。
用户进程启动后,它如何与内核通信?所有内核服务都通过系统调用暴露。下面深入分析 SVC 机制的完整路径。
5. 系统调用机制:用户态到内核态的桥梁
5.1 为什么需要系统调用?
用户进程运行在 USR 模式,无法直接访问内核内存、执行特权指令或操作硬件。所有内核服务(文件 I/O、信号、信号量等)都必须通过系统调用——用户代码触发 SVC 异常,CPU 自动切换到 SVC 模式(特权态),内核代码执行请求后返回结果。
5.2 Proxy/Stub 架构
NuttX 的系统调用分为三层:
1 | User space: write(fd, buf, n) [app code] |
上图展示了系统调用的三层结构:用户空间的 Proxy 负责将普通函数调用打包为 SVC 指令;内核空间的 Stub 负责将 SVC 参数解包并调用真正的内核函数。两者之间通过 ARM 的 SVC 异常机制跨越特权级边界。
Proxy(代理)在用户空间运行,将函数调用转换为 SVC 指令。Stub(桩函数)在内核空间运行,将 SVC 参数还原为函数调用。两者都从 syscall/syscall.csv 自动生成。
5.3 SVC 入口(汇编)
文件:arch/arm/src/armv7-a/arm_vectors.S:294-386
1 | arm_vectorsvc: |
add r1, sp, #(XCPTCONTEXT_SIZE - 4*REG_R0) 这行是关键:此时 sp 已经被 srsdb(-8 字节)和 stmdb {r0-r12}(-52 字节)向下推过了,不再是用户的原始栈顶。这条 add 指令通过加上已压入的偏移量,反算出用户异常前的真实 SP,暂存到 r1 中。随后 stmdb sp!, {r1, r14} 将这个修正值和 SYS 模式的 lr(= 用户 LR,因为 SYS 和 USR 共享 lr)一起压入栈帧。
RFEIA(Return From Exception, Increment After)从内存加载 PC 和 CPSR,CPU 根据 CPSR 中的 mode 位自动切换回用户态。
栈帧变化示意图(选读):
以下展示 SVC 入口(压栈)和出口(出栈)时 SYS 模式栈的变化过程。SYS 模式与 USR 模式共享 sp/lr,因此保存的就是用户任务的执行现场。
1 | =============================================================== |
整个过程中,寄存器帧在 SYS/USR 栈上形成一个固定布局的结构体,C 代码通过 regs[REG_R0]、regs[REG_PC] 等宏下标直接读写。如果 arm_syscall() 将 regs 指针换成另一个 TCB 的 xcp.regs,出栈时就恢复到另一个任务的上下文——上下文切换就此完成。
5.4 系统调用 C 分发:arm_syscall()
文件:arch/arm/src/armv7-a/arm_syscall.c:162-579
arm_syscall(regs) 是所有 SVC 的统一 C 入口。它从 regs[REG_R0] 读取系统调用号(即用户放在 R0 中的值),然后用 switch-case 分发处理。NuttX 定义了两类 syscall 号:
- 内部 syscall(编号 1-7):内核自用,不暴露给用户空间,用于上下文切换、任务启动等
- 库 syscall(编号 >=
CONFIG_SYS_RESERVED,通常 >= 8):对应 POSIX API(open、write、sem_wait等)
| 系统调用号 | 用途 | 关键操作 |
|---|---|---|
SYS_restore_context (1) |
恢复上下文 | 切换地址环境 + 加载新寄存器 |
SYS_switch_context (2) |
上下文切换 | 调用 nxsched_switch_context() |
SYS_syscall_return (3) |
系统调用返回 | 恢复用户态 CPSR + 用户栈 |
SYS_task_start (4) |
启动用户任务 | 设置 CPSR = USR 模式 |
SYS_pthread_start (5) |
启动 pthread | 同上 |
>= CONFIG_SYS_RESERVED (8+) |
库系统调用 | 保存现场 + 内核栈切换 + 转发到 dispatch_syscall |
下图展示了一次库系统调用(以 write() 为例)的完整时序,包括两次 SVC、内核栈切换的生效时机、以及各阶段运行在哪个栈上:
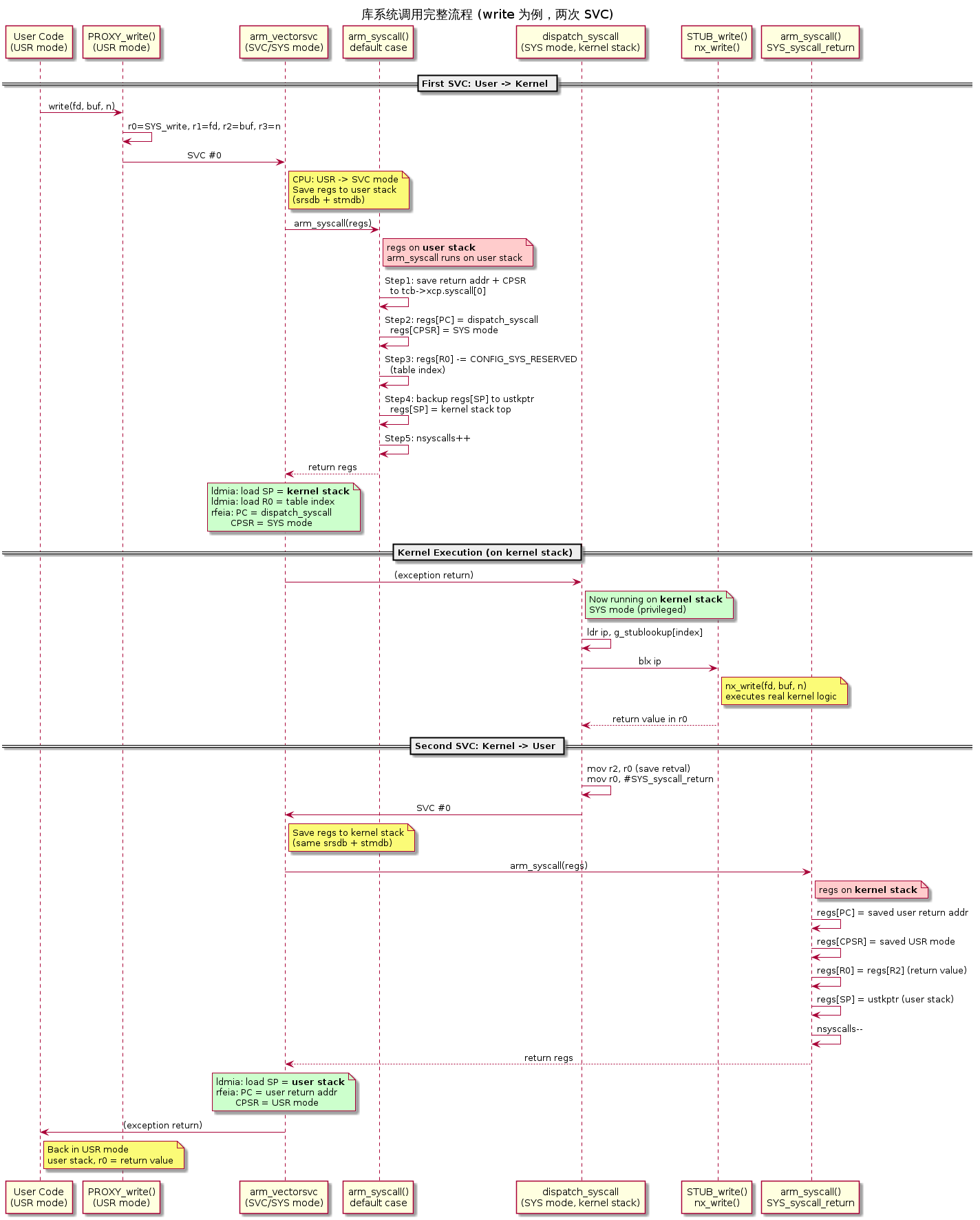
5.5 arm_syscall() 处理库 syscall 的完整逻辑(default case)
当用户调用 write()、sem_wait() 等库函数时,走的是 default: 分支。这是最常见的路径,也是最复杂的——它需要做 5 件事才能安全地从用户态进入内核执行真正的服务。
文件:arch/arm/src/armv7-a/arm_syscall.c:493-556(以下为关键行摘录)
1 | default: /* cmd >= CONFIG_SYS_RESERVED, 库 syscall */ |
逐步解释:
- Step 1:将用户代码的返回地址和 CPSR 存到
tcb->xcp.syscall[]数组中。这些信息在第二次 SVC(SYS_syscall_return)时用来恢复——让 CPU 回到用户代码的正确位置和模式。 - Step 2:把帧中的 PC 改成
dispatch_syscall的地址、CPSR 改成 SYS 模式。这样当arm_vectorsvc汇编恢复寄存器并rfeia返回时,CPU 会跳到dispatch_syscall并以特权模式运行。 - Step 3:把 R0 从原始 syscall 号减去保留数,变成
g_stublookup[]表的索引。dispatch_syscall会用这个索引查表。 - Step 4:把帧中的 SP 从用户栈改为内核栈。效果同 Step 2——不是立即切换,而是等汇编
ldmia恢复寄存器时生效。用户原始 SP 备份到ustkptr,日后恢复用。 - Step 5:
nsyscalls++支持嵌套(虽然极少出现)。index == 0表示是最外层 syscall,只有最外层才做栈切换。
arm_syscall() 返回后发生了什么?
arm_syscall() 返回 regs 指针给汇编代码。汇编执行:
1 | ldmia r0, {r13, r14}^ → USR_sp = regs[REG_SP] = 内核栈顶 |
此时 CPU 以 SYS 模式、内核栈,跳转到 dispatch_syscall 执行。
5.6 arm_syscall() 处理 SYS_syscall_return(返回用户态)
dispatch_syscall 执行完桩函数后,触发第二次 SVC(SYS_syscall_return),再次进入 arm_syscall():
文件:arch/arm/src/armv7-a/arm_syscall.c:218-267
1 | case SYS_syscall_return: |
之后汇编再次恢复寄存器并 rfeia——这次 CPSR 是 USR mode,PC 是用户代码地址,SP 是用户栈。CPU 以非特权模式回到用户代码,R0 携带返回值。
5.7 dispatch_syscall:裸函数跳板
经过 5.5 节的 default case 处理后,SVC 返回时 CPU 以 SYS 模式、内核栈、R0=表索引,跳转到这个裸函数(naked function,无栈帧开销):
文件:arch/arm/src/armv7-a/arm_syscall.c:125-144
1 | dispatch_syscall: |
完整的 syscall 路径涉及两次 SVC:
- 第一次 SVC:用户态 -> 内核态,设置内核栈,跳转到
dispatch_syscall dispatch_syscall调用桩函数,执行真正的内核逻辑- 第二次 SVC(
SYS_syscall_return):恢复用户态 CPSR 和用户栈,返回用户代码
实例:write(1, “hello”, 5) 的完整 syscall 路径
1 | 用户态 PROXY_write(): |
系统调用机制解决了用户进程与内核之间的通信问题。而当多个进程都准备好运行时,调度器决定谁先获得 CPU。
6. 调度算法:优先级有序链表
6.1 调度算法在 KERNEL 模式下有何不同?
调度算法的核心逻辑在所有构建模式下完全相同——优先级最高的就绪任务运行。差异在于调度决策的执行路径:在 KERNEL 模式下,每次上下文切换除了保存/恢复寄存器,还需要切换地址环境(TTBR0)。
6.2 核心数据结构:优先级有序双向链表
文件:sched/sched/sched.h:168
1 | extern dq_queue_t g_readytorun; /* 就绪队列(按优先级降序)*/ |
链表头 = 当前最高优先级任务 = 当前运行的任务。所有调度决策归结为:谁在链表头。
6.3 优先级有序插入
文件:sched/sched/sched.h:456-533
1 | static inline_function bool nxsched_add_prioritized(FAR struct tcb_s *tcb, |
循环条件 sched_priority <= next->sched_priority 确保相同优先级的新任务插入到同优先级组末尾——这是 SCHED_RR 轮转的基础。
6.4 加入就绪队列
文件:sched/sched/sched_addreadytorun.c:69-121
1 | bool nxsched_add_readytorun(FAR struct tcb_s *btcb) |
返回 true 时,调用者执行 up_switch_context() 触发上下文切换。
调度器做出了”切换到谁”的决策后,up_switch_context() 负责实际执行切换。在 KERNEL 模式下,这不仅涉及寄存器保存/恢复,还需要切换整个地址空间。
7. 上下文切换:寄存器 + 地址环境双切换
7.1 KERNEL 模式下上下文切换的额外开销
在 FLAT 模式下,上下文切换只需保存/恢复寄存器。在 KERNEL 模式下,还需要:
- 刷新 D-Cache + 无效化 I-Cache(确保旧进程的脏数据可见、旧指令不残留)
- 写 TTBR0(切换到新进程的 L1 页表)
- 无效化 TLB(旧地址翻译条目不再有效)
7.2 addrenv_switch():地址环境切换的核心
文件:sched/addrenv/addrenv.c:125-196
1 | int addrenv_switch(FAR struct tcb_s *tcb) |
addrenv_switch() 的核心逻辑:首先检查目标任务是否是内核线程(next == NULL 则无需切换);如果当前 CPU 上激活的地址环境与目标不同,则刷新 Cache、写 TTBR0 切换页表、无效化 TLB。旧环境的引用计数通过工作队列延迟减少——避免在中断/SVC 上下文中执行可能阻塞的物理页释放操作。
7.3 上下文切换调用点
文件:arch/arm/src/armv7-a/arm_syscall.c:269-296
1 | case SYS_switch_context: |
文件:arch/arm/src/armv7-a/arm_doirq.c:89-101(中断返回路径)
1 | if (regs != tcb->xcp.regs) /* 检测到上下文切换 */ |
7.4 完整的上下文切换时序
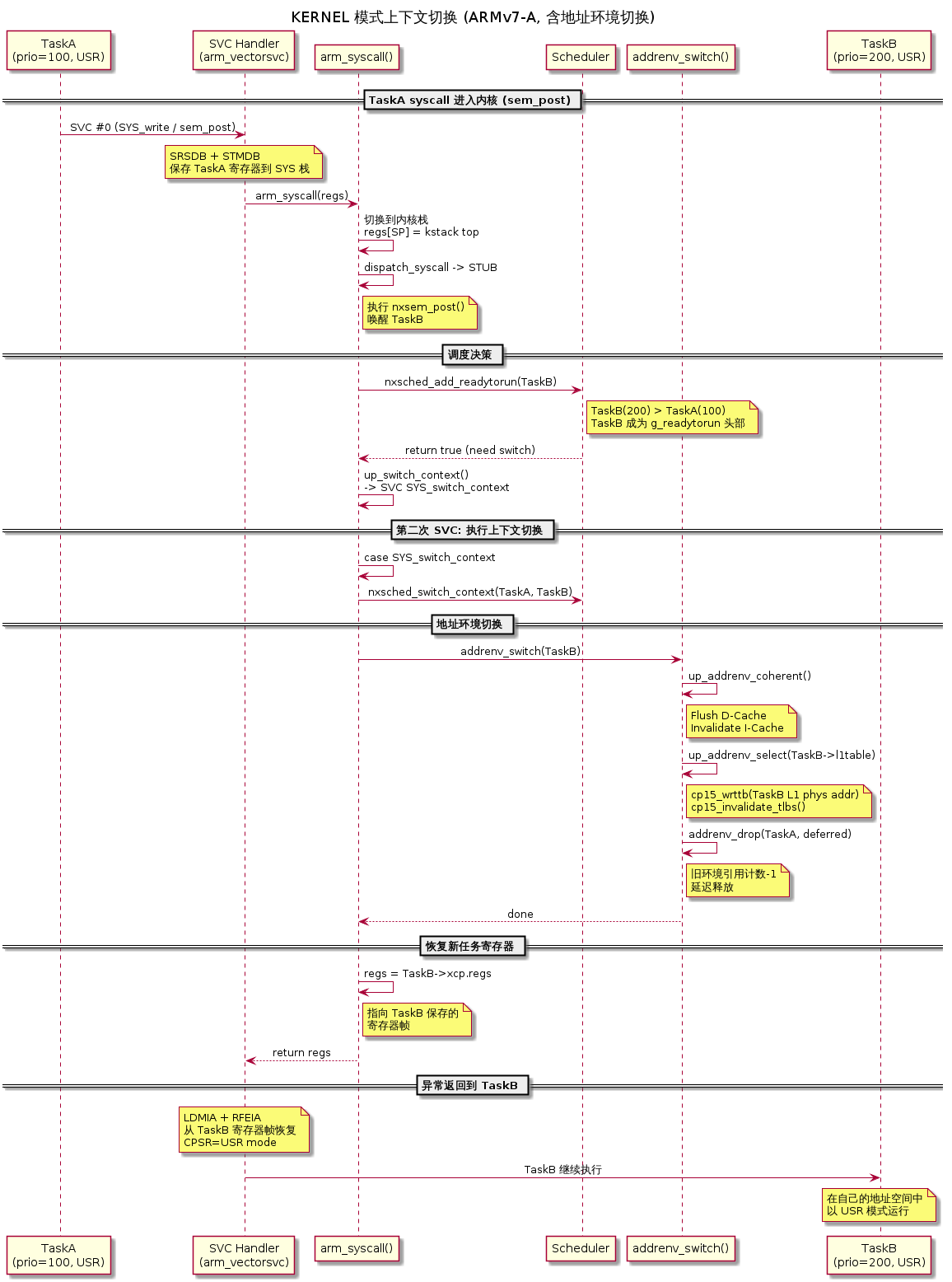
场景:TaskA(prio=100, 用户进程)释放信号量,唤醒 TaskB(prio=200, 另一个用户进程)
1 | TaskA 在内核态执行 nxsem_post()(通过 syscall 进入内核) |
关键时序约束:addrenv_switch() 必须在加载新任务的寄存器之前完成——否则新任务的用户栈地址在旧的页表下可能无效。
上下文切换解决了”运行哪个任务”的问题。但如果多个任务具有相同优先级,谁先运行?这就是时间片轮转要解决的公平性问题。
8. 时间片轮转:SCHED_RR
8.1 工作原理
SCHED_RR 在 KERNEL 模式下与 FLAT 模式完全相同——调度算法不区分构建模式。每个 tick 中断递减当前任务的 timeslice,到期时将任务移到同优先级组末尾。
文件:sched/sched/sched_roundrobin.c:127-230
1 | clock_t nxsched_process_roundrobin(FAR struct tcb_s *tcb, clock_t ticks, |
轮转的实现技巧:nxsched_reprioritize_rtr(tcb, same_priority) 先移除再重新插入——由于插入逻辑将相同优先级的新节点放在组末尾,效果就是当前任务让位给了下一个同优先级任务。
时间片保证了同优先级任务间的公平,但如果低优先级任务持有高优先级任务需要的资源,还需要优先级继承来避免反转。
9. 优先级继承:解决优先级反转
9.1 问题与解决方案
优先级反转:低优先级任务 L 持有信号量,高优先级任务 H 等待,中优先级任务 M 抢占 L——H 被 M 间接阻塞。
NuttX 的解决方案:当 H 阻塞在 L 持有的信号量上时,将 L 的优先级临时提升到 H 的级别。
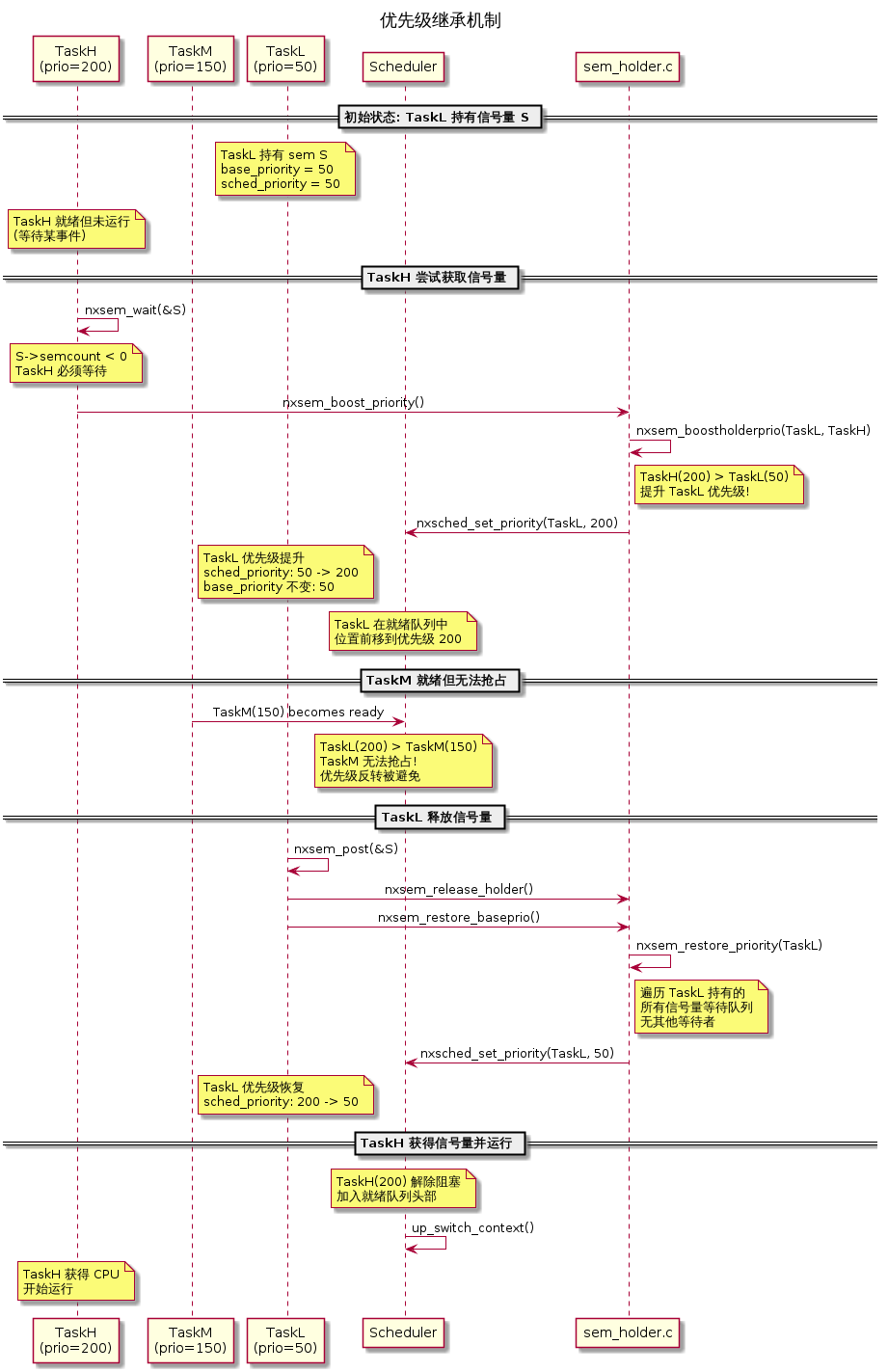
9.2 提升逻辑
文件:sched/semaphore/sem_holder.c:315-338
1 | static int nxsem_boostholderprio(FAR struct semholder_s *pholder, |
9.3 恢复逻辑
文件:sched/semaphore/sem_holder.c:391-434
1 | static void nxsem_restore_priority(FAR struct tcb_s *htcb) |
恢复时不能简单回到 base_priority——任务可能同时持有多个信号量。必须找到所有仍在等待的最高优先级作为新的运行优先级。
优先级继承解决了资源竞争导致的优先级反转问题。而 sched_lock() 则提供了一种更轻量的方式来保护内核内部的短临界区。
10. 抢占控制:sched_lock/unlock
10.1 为什么 sched_lock 在 KERNEL 模式下仍然重要?
即使有 MMU 保护,内核内部的临界区仍然需要防止任务切换。例如,修改链表指针的中间状态不能被中断。sched_lock() 是比关中断更轻量的选择——它允许中断响应但禁止任务切换。
文件:sched/sched/sched_lock.c:67-99
1 | void sched_lock(void) |
文件:sched/sched/sched_unlock.c:57-180
1 | void sched_unlock(void) |
sched_lock() 期间,高优先级新就绪任务被暂存到 g_pendingtasks。sched_unlock() 时统一合并,确保延迟最小化。
10.2 机制详解:lockcount 如何阻止抢占(选读)
sched_lock/unlock 不涉及任何硬件操作,它是调度器内部的一个软件约定:TCB 中的 lockcount 字段充当”请勿打扰”标志。
1 | lockcount == 0 → 调度器正常工作,高优先级任务可以随时抢占 |
“锁”的生效点不在 sched_lock() 本身(它只是递增计数器),而在 nxsched_add_readytorun()——调度器每次将新任务放入就绪队列时,都会检查当前任务的 lockcount:
文件:sched/sched/sched_addreadytorun.c:80-89
1 | if (nxsched_islocked_tcb(rtcb) && |
场景演示:TaskA(prio=100)在 lock 保护下修改内核链表
1 | 时刻 T0: TaskA 调用 sched_lock() |
与关中断(disable_irq)的对比:
| 特性 | sched_lock() | enter_critical_section() |
|---|---|---|
| 中断响应 | 正常响应 | 被屏蔽 |
| 保护范围 | 仅防止被抢占 | 防止中断 + 防止抢占 |
| 对实时性的影响 | 中断延迟不受影响 | 增加中断响应延迟 |
| 可嵌套 | 是(计数器) | 是(BASEPRI 保存/恢复) |
| 适用场景 | 内核链表操作等短临界区 | 必须保证原子性的硬件操作 |
需要注意:sched_lock() 只防止被动抢占(别人抢占我),不防止主动让出——如果在 lock 期间调用了 sem_wait() 等阻塞操作,当前任务仍然会被切走。
11. 对比:KERNEL 模式 vs FLAT 模式 vs Linux
| 特性 | NuttX FLAT | NuttX KERNEL | Linux |
|---|---|---|---|
| 地址空间 | 全局共享 | 每进程独立 L1 页表 | 每进程独立 pgd |
| 进程创建 | task_create() |
posix_spawn() / exec() |
fork() + exec() |
| 特权级 | 全部 SYS 模式 | 用户 USR / 内核 SYS | 用户 Ring3 / 内核 Ring0 |
| 系统调用 | 直接函数调用 | SVC + Proxy/Stub | SWI/SVC + syscall table |
| 内核栈 | 不需要 | 每用户进程一个 | 每线程一个(8KB/16KB) |
| TLB 管理 | 无 | 切换时全无效化 | ASID 避免全无效化 |
| 页表大小 | 无 | 16KB L1 + L2 pages | 多级(PGD/PUD/PMD/PTE) |
| 堆管理 | 全局内核堆 | 每进程用户堆 + 内核堆 | 每进程用户堆 + SLAB |
| 内存保护 | 无 | MMU 硬件强制 | MMU 硬件强制 |
| 上下文切换开销 | 寄存器保存/恢复 | + Cache flush + TTBR0 写 + TLB 无效化 | + ASID 切换(轻量) |
**NuttX KERNEL 模式是 Linux 进程模型的”精简版”**——保留了核心的地址空间隔离和特权级分离,但省略了 Copy-on-Write、demand paging、ASID 等优化。适合对安全性有要求但资源仍然有限的 ARMv7-A SoC(如 SAMA5D、i.MX6UL)。
12. 关键要点
KERNEL 模式下
task_create()被禁用——用户进程只能通过posix_spawn()/exec()从 ELF 文件创建,因为每个进程需要独立的虚拟地址空间。每个用户进程拥有完整的 16KB L1 页表,从内核主页表复制而来(继承内核映射),然后叠加 .text/.data/heap/stack 的 L2 页表条目。
地址环境切换 = 写 TTBR0 + 无效化 TLB——两条 CP15 指令完成整个虚拟地址空间的切换。
用户进程有双栈:用户栈(在用户地址空间,进程间隔离)+ 内核栈(在内核地址空间,syscall 期间使用)。
系统调用经历两次 SVC:第一次从用户态进入内核态执行服务;第二次(
SYS_syscall_return)从内核态返回用户态。首次运行用户进程通过
SYS_task_start将 CPSR mode 位从 SYS 改为 USR,异常返回时 CPU 自动降级到非特权模式。调度算法本身不区分构建模式——优先级有序链表、抢占控制、时间片轮转、优先级继承的实现完全相同。差异仅在上下文切换的”最后一公里”(地址环境切换)。
引用计数保护地址环境生命周期——pthread 共享父进程的 addrenv,最后一个线程退出时通过工作队列延迟释放物理页。
13. 参考文件索引
| 文件路径 | 关键内容 | 引用行号 |
|---|---|---|
include/nuttx/sched.h |
TCB 结构体、addrenv 字段、flags | 91-112, 593-598 |
include/nuttx/addrenv.h |
addrenv_s 结构体、虚拟布局宏 | 268-275, 56-253 |
arch/arm/include/arch.h |
arch_addrenv_s(L1 页表指针) | 134-159 |
arch/arm/include/armv7-a/irq.h |
xcptcontext(kstack/ustkptr) | 328-331 |
arch/arm/include/syscall.h |
sys_call0-6 宏(SVC 内联汇编) | 156-421 |
arch/arm/src/armv7-a/arm_addrenv.c |
up_addrenv_create/select/destroy | 167-256, 453-460, 274-314 |
arch/arm/src/armv7-a/arm_addrenv_utils.c |
arm_addrenv_create_region | 60-151 |
arch/arm/src/armv7-a/arm_addrenv_kstack.c |
内核栈分配 | 133-149 |
arch/arm/src/armv7-a/arm_addrenv_ustack.c |
用户栈分配 | 130-158 |
arch/arm/src/armv7-a/arm_syscall.c |
SVC C 处理器、dispatch_syscall | 125-579 |
arch/arm/src/armv7-a/arm_vectors.S |
SVC 汇编入口 arm_vectorsvc | 294-386 |
arch/arm/src/armv7-a/arm_doirq.c |
中断返回路径(含 addrenv_switch) | 89-101 |
arch/arm/src/armv7-a/arm_initialstate.c |
初始 CPSR 设置 | 55-161 |
arch/arm/src/armv7-a/mmu.h |
mmu_l1_setpgtable(写 TTBR0) | 1408-1411 |
arch/arm/src/common/arm_task_start.c |
up_task_start(降级到 USR) | 67-74 |
sched/addrenv/addrenv.c |
addrenv_switch(OS 层切换) | 125-196 |
sched/sched/sched_addreadytorun.c |
加入就绪队列 | 69-121 |
sched/sched/sched.h |
nxsched_add_prioritized 内联函数 | 456-533 |
sched/sched/sched_roundrobin.c |
SCHED_RR 时间片处理 | 127-230 |
sched/sched/sched_lock.c / sched_unlock.c |
抢占控制 | 67-99 / 57-180 |
sched/semaphore/sem_holder.c |
优先级继承 | 315-338, 391-434 |
sched/task/task_create.c |
task_create 禁用(KERNEL 模式) | 200 |
sched/task/task_start.c |
nxtask_start(分发到 up_task_start) | 68-113 |
sched/task/task_init.c |
内核栈分配条件 | 167-178 |
sched/task/task_posixspawn.c |
posix_spawn 入口 | 218-226 |
binfmt/binfmt_exec.c |
exec_internal / exec_spawn | 77-156 |
binfmt/binfmt_execmodule.c |
exec_module(进程启动核心) | 152-381 |
binfmt/elf.c |
ELF 加载入口 | 93-238 |
libs/libc/elf/elf_load.c |
libelf_load_with_addrenv | 701-776 |
libs/libc/elf/elf_addrenv.c |
libelf_addrenv_alloc | 83-143 |
syscall/syscall_stublookup.c |
桩函数查找表 | 88-95 |
Documentation/implementation/processes_vs_tasks.rst |
官方进程模型文档 | 全文 |