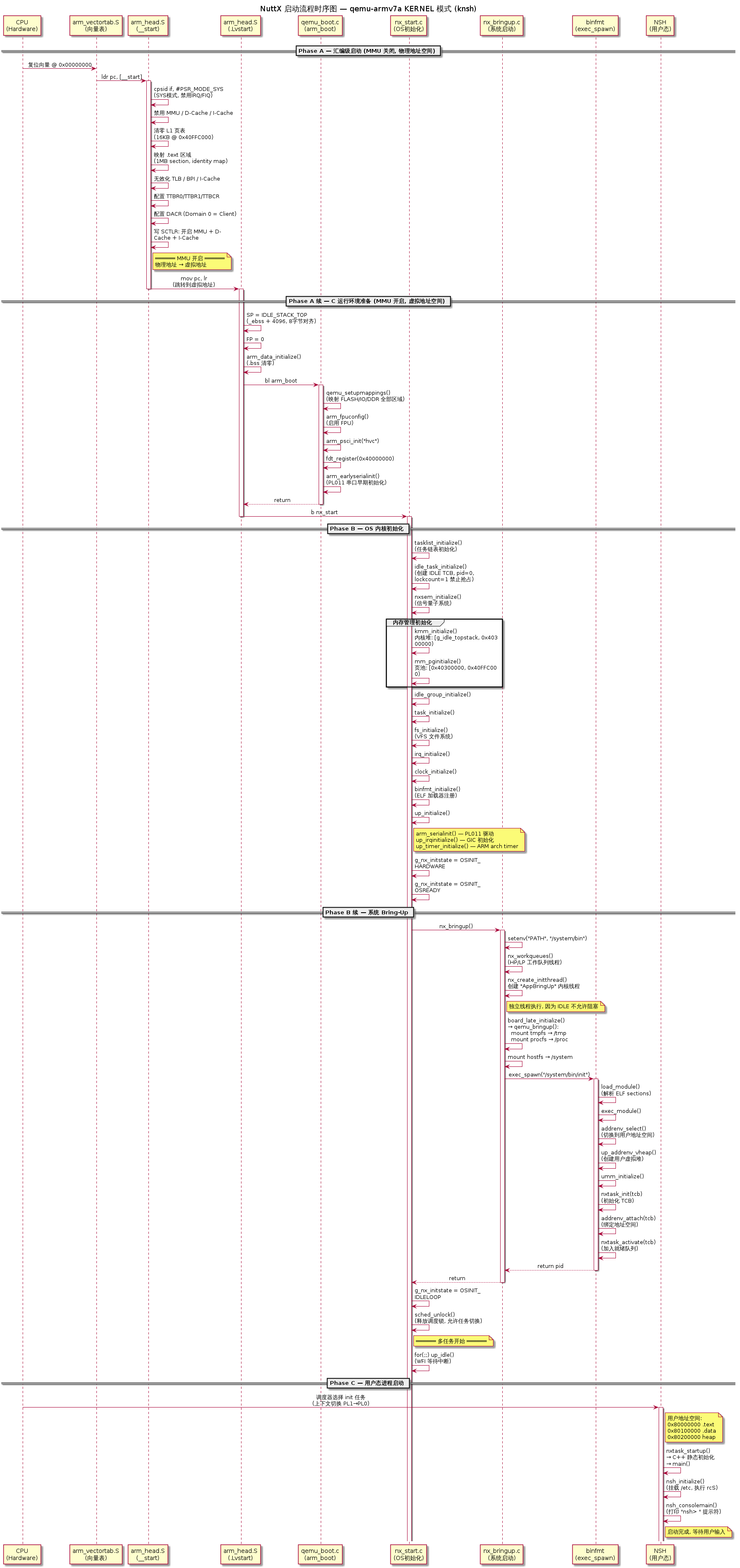
Nuttx - Boot Flow
从 CPU 上电复位到 NSH Shell 出现提示符,NuttX 内核经历了汇编级 MMU 初始化、OS 子系统逐层构建、ELF 可执行文件加载和用户态地址空间创建四个阶段。本文以
qemu-armv7a:knsh配置为实例,逐行追踪完整的启动调用链。
1. 启动流程全景
处理器上电后,要运行一个用户程序(比如 shell),需要解决三个问题:
- 硬件就绪:CPU 从物理地址执行,没有 MMU 映射,没有 C 运行环境(栈、.bss、.data)。
- OS 就绪:需要初始化调度器、内存管理、文件系统、中断、时钟等 OS 子系统。
- 用户程序就绪:KERNEL 模式下,用户程序是独立的 ELF 可执行文件,需要加载、创建独立的地址空间、从内核态切换到用户态执行。
NuttX 官方文档将这一过程划分为三个 Phase(参见 Documentation/implementation/nuttx_initialization_sequence.rst),再加上 KERNEL 模式特有的用户态准备,实际形成 四个阶段:
1 | Physical Address Space Virtual Address Space |
与 Linux 的对比:Linux 启动分为 bootloader → kernel decompression → start_kernel() → rest_init() → init 进程,整体结构类似,但 NuttX 的实现更紧凑——整个启动过程从头到尾在一个函数调用链中完成,直到 exec_spawn() 才创建第一个用户态进程。
下面我们逐阶段深入源代码。
2. Phase A — 汇编级启动:从复位到 C 函数
2.1 为什么需要汇编启动?
C 语言需要栈才能运行,需要已初始化的全局变量(.data)和已清零的未初始化变量(.bss)。在 CPU 上电瞬间,这些都不存在。此外,ARMv7-A 处理器刚上电时 MMU 是关闭的,所有地址都是物理地址。我们需要用汇编语言准备 C 运行环境,并建立 MMU 页表,才能跳转到 C 代码。
2.2 复位向量:第一条指令
ARMv7-A 的复位向量在地址 0x00000000(低向量配置,CONFIG_ARCH_LOWVECTORS=y)。链接脚本将 .vectors 段放在镜像最开头:
1 | dramboot.ld:55 *(.vectors) → ROM 起始位置 (0x00000000) |
向量表位于 arch/arm/src/armv7-a/arm_vectortab.S:60-73,跳转目标地址定义在 :84-99:
1 | arm_vectortab.S:60-73 |
这些跳转目标在编译时由链接器填充(arm_vectortab.S:84-99):
1 | arm_vectortab.S:84-99 |
每条 ldr pc, ... 指令从紧跟的 .long 地址加载处理函数入口并跳转。复位向量指向 __start 函数,位于 arch/arm/src/armv7-a/arm_head.S:181。
与 Cortex-M 的不同:Cortex-M 的向量表前两项是”初始 SP + 复位入口地址”,硬件自动加载 SP 再跳转。Cortex-A 没有这个硬件约定,需要软件自行处理所有事情。
2.3 __start:建立 MMU 页表
__start 是第一个被执行的函数,它要完成的任务是:在物理地址空间中,手工填写 L1 页表,然后打开 MMU,让 CPU 切换到虚拟地址空间运行。
2.3.1 进入安全状态
1 | arm_head.S:220-232 |
为什么要禁用 MMU 再重新配置?上电后的 SCTLR 状态是不确定的(可能被 bootloader 修改过),必须重置到已知状态。此外,在填写页表期间 MMU 必须关闭,否则 TLB 中可能残留旧的映射。
2.3.2 清零 L1 页表
页表位于物理地址 PGTABLE_BASE_PADDR,这个值是由 chip.h:45 计算出来的:
1 | chip.h:44-49 |
代入实际值:CONFIG_RAM_START=0x40000000,CONFIG_RAM_SIZE=16777216 (16MB),CONFIG_SMP_NCPUS=1,所以页表位于 0x40FFC000——物理 RAM 的最顶端。这是因为低向量表要放在 0x00000000,页表如果也放在低地址会冲突,所以放在高地址。
1 | arm_head.S:237-248 |
这里使用循环展开(4 个 str 一组)来加速清零,避免分支预测失败的开销。
2.3.3 映射内核 .text 区域
ARMv7-A 的 L1 页表使用 段(section) 映射,每个 32-bit 页表项映射 1MB 地址空间。虚拟地址的 [31:20] 位作为页表索引。
对于 knsh 配置,镜像直接加载到 RAM 中运行(CONFIG_BOOT_RUNFROMFLASH=n),FLASH 和 RAM 物理地址相同(identity mapping),所以 CONFIG_IDENTITY_TEXTMAP=1。这意味着不需要创建临时 identity 映射。
1 | arm_head.S:285-321 |
实例 — 第一个页表项的构造:
1 | 页表基址 = 0x40FFC000 |
实际 MMU_MEMFLAGS 的完整拼装(arch/arm/src/armv7-a/mmu.h:610-615):
1 | mmu.h:610-615 |
PMD_TYPE_SECT(值为 2)标记这是一个 1MB 段描述符。PMD_SECT_AP_RW1 设置 AP[1:0]=01,表示只有 PL1(内核态)可以读写,PL0(用户态)无访问权限——这保证了内核内存不被用户进程访问。
2.3.4 无效化 TLB 和 Cache
填写完页表后,必须无效化所有 TLB(转换后备缓冲器),因为 CPU 可能缓存了旧的映射。同时无效化分支预测器和 I-Cache:
1 | arm_head.S:377-389 |
TLBIALLIS 的 IS 后缀表示操作广播到 Inner Shareable 域内的所有 CPU 核心——这在多核(SMP)场景下是必要的。isb(指令同步屏障)保证后续指令能看到 TLB 已清空。接下来就可以安全地配置 MMU 寄存器了。
2.3.5 配置 MMU 寄存器并开启
设置完 TLB 后,需要配置一系列 CP15 协处理器寄存器,将页表地址告诉 MMU,然后打开 MMU 和 Cache。以下代码取自 arm_head.S:407-559,展示了 knsh 配置下的有效执行路径(完整源代码中有多个 #ifdef 分支处理 SMP、Cortex-A5、高向量、对齐陷阱、大小端等变体,此处只保留 knsh 实际走的分支):
1 | arm_head.S:407-559 |
关键一步:mov pc, lr 后,CPU 正式在虚拟地址空间中运行。由于我们做了 identity mapping(物理地址 = 虚拟地址),代码可以无缝继续执行。
2.4 .Lvstart:准备 C 运行环境
进入 .Lvstart(arm_head.S:660)后,MMU 已开启,我们需要建立栈并初始化数据段:
1 | arm_head.S:660-708 |
栈指针指向 IDLE_STACK_TOP,其定义在 arm_head.S:37-45:
1 | arm_head.S:37-45 |
_ebss 由链接脚本定义(dramboot.ld:115-120),位于 .bss 段的末尾。栈向下增长,栈顶在 _ebss + 4096 处。内核堆从 g_idle_topstack(即 IDLE_STACK_TOP)开始向上延伸。
实例 — 内存布局计算:
1 | 假设 .text + .rodata 共占用 0x20000 (128KB) |
arm_data_initialize 函数(arm_head.S:719-755)负责清零 .bss 段:
1 | arm_head.S:719-731 |
由于 knsh 配置下镜像直接加载到 RAM(不是从 Flash 运行),.data 的初始值已经在加载时被 QEMU 放入正确位置,所以 CONFIG_BOOT_RUNFROMFLASH 为假,不需要复制 .data。
做完 .bss 清零后,汇编阶段的最后一步是调用 arm_boot() 跳入 C 世界。这标志着从纯粹的手工寄存器操作过渡到结构化的平台初始化代码。
3. Phase A 续 — arm_boot():平台级 C 初始化
__start 在汇编阶段只是”够用就行”地映射了内核代码所在的 1MB 区域。如果要让操作系统正常工作,还需要访问 MMIO 外设寄存器(如 GIC 中断控制器、UART 串口)、配置浮点单元、以及让剩余的所有物理内存区域都变得可访问。这些工作无法全在汇编中完成——C 语言的表达能力远强于汇编,而且 MMU 映射 API (mmu_l1_map_regions) 本身就是 C 函数。
因此 .Lvstart 调用 arm_boot()(arch/arm/src/qemu/qemu_boot.c:77),把后续的平台初始化交给 C 代码:
1 | qemu_boot.c:77,88-112 |
(完整函数还包含 CONFIG_ARCH_PERF_EVENTS、CONFIG_SMP、CONFIG_BUILD_PROTECTED 等条件编译分支,knsh 配置下均不生效。)
这五个初始化步骤中,对启动流程最关键的是 qemu_setupmappings()——它把 QEMU virt 平台上的全部物理内存和外设区域映射进 MMU 页表。之后初始化 FPU(否则浮点指令会触发未定义异常)和串口(否则看不到任何输出)。
3.1 完善 MMU 映射 — qemu_setupmappings()
QEMU virt 平台的物理内存布局如下(qemu_memorymap.h:43-63):
1 | 0x00000000 ──────────────── Flash (128MB) |
qemu_setupmappings() 遍历预定义的映射表,为所有区域建立 L1 段映射:
1 | qemu_memorymap.c:44-85 |
注意 I/O 区域使用 MMU_IOFLAGS(Device 类型,禁止缓存、禁止执行),而内存区域使用 MMU_MEMFLAGS(Write-Back 缓存、允许执行)。所有区域都是 identity mapping(虚拟地址 = 物理地址),因为 VIRT_*_VSECTION == VIRT_*_PSECTION。
为什么 identity mapping? KERNEL 模式中,内核运行在 PL1 特权级,访问物理地址等同于访问虚拟地址。用户态进程才有独立的虚拟地址空间(0x80000000 起)。这种设计简化了内核驱动编写——内核可以直接使用物理地址访问设备寄存器。
至此,硬件层面的一切准备就绪:MMU 已开启、所有物理区域已映射、FPU 和串口已配置。接下来,执行流进入 nx_start(),从”平台初始化”切换到”操作系统构建”阶段。
4. Phase B — nx_start():OS 内核初始化
nx_start() 是整个 NuttX 内核的入口,位于 sched/init/nx_start.c:502。它是所有初始化步骤的编排器,按照严格的顺序逐层构建 OS 基础设施。
4.1 初始化状态机
NuttX 使用 g_nx_initstate 全局变量跟踪初始化进度(include/nuttx/init.h:57-78):
1 | OSINIT_POWERUP (0) → 刚上电 |
每个阶段的切换都很关键——后续代码可以通过 OSINIT_MM_READY() 等宏检查某个子系统是否已经就绪。
4.2 创建 IDLE 任务
IDLE 任务是系统中优先级最低(priority=0)且永远不可被阻塞的特殊任务。它有两个功能:
- 在系统无其他任务可运行时占位(防止调度器空转)
- 作为所有后续任务的”祖先”——子任务继承其环境变量和文件描述符
idle_task_initialize() 在 nx_start.c:328-420。以下展示核心逻辑(完整函数还包含 SMP 多 CPU IDLE 栈分配、名称设置和 per-CPU 寄存器更新,为简洁省略了相关代码路径):
1 | nx_start.c:328,336-347,355-366,372-387,405-413 |
关键设计:nx_start 就是 CPU0 IDLE 任务的入口函数。这意味着整个 OS 初始化(Phase B)都是在 IDLE 任务的上下文中完成的。这解释了为什么初始化期间是单线程的——IDLE 线程在执行初始化,还没有其他线程存在。
4.3 内存管理器初始化
内存初始化是第二步(因为后续所有子系统都需要动态分配内存):
1 | nx_start.c:540-575 |
对于 knsh 配置,实际的内存布局由 qemu_allocateheap.c 和 qemu_pgalloc.c 定义:
1 | 0x40000000 ┌───────────────────────────────┐ RAM_START |
实例 — 内核堆的起止地址(来自 arm_allocateheap.c:155-180):
1 | arm_allocateheap.c:155-180 |
代入 knsh 的实际值:g_idle_topstack 紧跟在 IDLE 栈之后(约 _ebss + 4096),CONFIG_ARCH_PGPOOL_PBASE = 0x40300000,所以内核堆从 IDLE 栈顶一直延伸到页池的起始位置(0x40300000),大小约 2~3 MB。堆的上方是页池,用于为用户态进程分配物理页。
4.4 OS 子系统初始化链
内存管理器就绪后,nx_start 按依赖关系依次初始化各子系统:
1 | nx_start.c:622-666 |
为什么这个顺序? 信号量必须最先初始化(nxsem_initialize() 在内存初始化前)。因为几乎所有后续子系统内部都依赖信号量进行同步。文件系统必须在设备驱动之前初始化,因为驱动需要向 VFS 注册 /dev/* 节点。
4.5 up_initialize():硬件驱动初始化
软件数据结构准备完毕,开始初始化真实硬件:
1 | nx_start.c:676 |
arm_initialize.c:62-121 实际上是硬件的集中初始化点。展示核心调用(完整函数还包含电源管理、DMA、coredump 等条件编译路径):
1 | arm_initialize.c:62,67,72,100,105,119 |
对于 qemu-armv7a,关键驱动初始化变为:
1 | qemu_irq.c:105 up_irqinitialize() /* 设置 VBAR, 初始化 GIC, 启用中断 */ |
中断初始化(qemu_irq.c:105)将 GIC 配置好,设置 VBAR(向量基址寄存器)指向异常向量表,然后向 CPU 使能 IRQ。从这一刻起,系统可以响应中断了。
4.6 状态记录
1 | g_nx_initstate = OSINIT_HARDWARE; /* nx_start.c:695, 硬件资源就绪 */ |
OS 基础设施(调度器、内存、文件系统、中断、时钟)已经就绪,但系统中还只有一个 IDLE 线程在运行。下一步 nx_bringup() 负责”激活”这个系统——创建工作队列、启动板级驱动、并创建第一个用户进程。
5. Phase B 续 — nx_bringup():系统 Bring-Up
nx_bringup()(sched/init/nx_bringup.c:496)在 nx_start 末尾被调用,完成从内核初始化到用户程序的最后一步。
5.1 设置环境变量
1 | nx_bringup.c:508-518 |
这些环境变量被设置为 IDLE 任务的环境,所有后续创建的子任务都会继承。
5.2 启动内核工作线程
1 | nx_bringup.c:526-539 |
nx_pgworker 在 CONFIG_LEGACY_PAGING 配置下创建页错误处理的内核线程,knsh 未启用此功能,所以实际被预处理器替换为空操作。nx_workqueues 启动高优先级和低优先级工作队列线程,用于设备驱动”下半部”(bottom half)处理。nx_create_initthread 是接下来创建用户进程的关键步骤。
5.3 创建应用初始化线程
nx_create_initthread()(nx_bringup.c:436-456)有两个路径:
**路径 A (knsh 采用)**:配置了 CONFIG_BOARD_LATE_INITIALIZE 时,创建一个独立的内核线程:
1 | pid = nxthread_create("AppBringUp", TCB_FLAG_TTYPE_KERNEL, |
nx_start_task(nx_bringup.c:410-416)在独立线程中执行 nx_start_application()。为什么要独立线程? IDLE 线程不允许阻塞(等待信号量、等待 I/O 等),而 board_late_initialize() 中可能需要挂载文件系统、初始化复杂设备——这些操作可能需要等待。独立线程可以安全地阻塞。
5.4 nx_start_application():启动用户程序
nx_start_application()(nx_bringup.c:297-391)是启动流程的核心转折点。以下摘取 knsh 实际执行的关键路径(CONFIG_INIT_FILE 分支),完整函数还包含 /etc ROMFS 挂载、coredump 初始化和 PROTECTED/FLAT 模式下的 task_spawn 路径:
1 | nx_bringup.c:316-324,362-387 |
board_late_initialize() → qemu_bringup()(qemu_bringup.c:161-211)挂载必要的文件系统:
1 | qemu_bringup.c:161-184 |
tmpfs 提供内存中的临时文件系统(用于 /tmp 等路径),procfs 提供进程信息伪文件系统(/proc/<pid>/)。这两个挂载点通常在用户程序启动前就绪,因为 NSH 和用户程序可能会用到。文件系统就绪后,最后一步是通过 exec_spawn 创建用户进程。
5.5 exec_spawn():KERNEL 模式的进程创建
在 KERNEL 模式(CONFIG_BUILD_KERNEL=y)下,task_spawn() 整个文件被编译排除(sched/task/task_spawn.c:46 受 #ifndef CONFIG_BUILD_KERNEL 保护)。用户进程只能通过 exec_spawn() 从文件系统加载 ELF 可执行文件来创建。
exec_spawn() 创建了系统中第一个用户态进程后,nx_bringup() 返回,IDLE 线程进入死循环等待被抢占。调度器发现就绪队列中有 init 任务,立即执行上下文切换,CPU 从内核态(PL1)切换到用户态(PL0),跳转到 ELF 文件的入口点。启动流程的接力棒正式从内核交给用户程序。
exec_spawn() 内部的执行路径反映了 binfmt 子系统的工作流程。先从文件系统加载 ELF 映像(load_module,解析 program headers 和 section headers),然后创建进程实例(exec_module)。创建过程中最关键的几步是:先用 addrenv_select 切换到新的用户地址空间,再用 up_addrenv_vheap 在用户虚拟地址上分配堆,最后 nxtask_activate 将任务加入就绪队列——此刻调度器可以在下一个时钟 tick 选择它运行。
1 | exec_spawn("/system/bin/init") [binfmt/binfmt_exec.c:193] |
用户态地址空间布局(来自 defconfig 中的 CONFIG_ARCH_* 值):
1 | Kernel Space (identity mapped, PL1 access): |
与 Linux 的对比:Linux 用户态从 0x08048000(32-bit)或 0x400000(64-bit)开始,内核态在高地址(0xC0000000 起)。NuttX ARM 的设计相反——内核在低地址做 identity mapping,用户态在高地址拥有独立的虚拟地址空间。这是 ARM MMU 的灵活性:每个进程可以有自己的 TTBR0。
5.6 用户程序入口
knsh 配置中 CONFIG_INIT_FILEPATH="/system/bin/init"。这个 init 程序实际上是 NSH (NuttShell),通过 hostfs 从开发机文件系统映射过来。
当 exec_module() 完成 TCB 初始化并调用 nxtask_activate() 后,init 任务进入就绪队列。然后 nx_bringup() 返回,nx_start() 的剩余部分继续:
1 | nx_start.c:751-771 |
sched_unlock() 是关键:整个初始化过程被 lockcount=1 锁住,不允许任务切换。开锁后,调度器会选择就绪队列中优先级最高的任务运行——即刚创建的 init 任务。
6. Phase C — 用户程序:NSH Shell 启动
init 任务的入口是 NSH 的 main 函数。在 nxtask_start()(sched/task/task_start.c:68)中,由于任务类型是 TCB_FLAG_TTYPE_TASK(而非 KERNEL),执行路径走 up_task_start():
1 | task_start.c:88-108 |
up_task_start() 是架构相关的汇编函数,设置 CPU 从 PL1(内核态)切换到 PL0(用户态),然后跳转到用户空间的入口函数。用户空间运行 nxtask_startup()(libs/libc/sched/task_startup.c:58),它调用 C++ 静态初始化,然后执行 main()。
NSH 的 main 在 apps/system/nsh/nsh_main.c。启动流程分两步:nsh_initialize() 完成一次性初始化(挂载 /etc ROMFS 并执行 rcS 启动脚本),然后 nsh_consolemain() 进入死循环,不断读取用户输入、解析命令、执行。nsh_consolemain() 不返回,因此 NSH 一旦启动就永远占据控制台。其启动流程如下(参见 nuttx_initialization_sequence.rst:572-651):
1 | nsh_main() |
这标志着整个启动流程的终点:从 CPU 上电到用户可以输入命令,所有的初始化工作已经完成。
7. 完整调用链总结
下面是 qemu-armv7a:knsh 从硬件复位到 NSH 提示符的完整路径。这个调用链可以按 MMU 状态分为两个大的半场:前半场(__start 到 .Lvstart 的 mov pc, lr)运行在物理地址空间,负责建立页表和启用 MMU;后半场(从 .Lvstart 开始)运行在虚拟地址空间,完成 OS 初始化和用户进程创建。最关键的两个转折点是 MMU 开启(地址空间从物理切换到虚拟)和 **exec_spawn**(从内核单线程切换到多任务、从内核空间创建出用户空间的第一个进程)。
1 | 复位向量 (0x00000000) |
理解了完整的调用链之后,我们来剖析几个贯穿整个启动流程的关键设计决策——这些决策决定了 NuttX KERNEL 模式与 FLAT 模式、乃至与 Linux 的本质区别。
8. 关键设计决策解析
8.1 KERNEL vs FLAT 模式的本质区别
| 特性 | FLAT 模式 | KERNEL 模式 (knsh) |
|---|---|---|
| 用户程序格式 | 与内核链接在一起 | 独立 ELF 文件 |
| 地址空间 | 共享同一个物理空间 | 用户态独立虚拟空间 |
| 进程创建 | task_spawn() |
exec_spawn() |
| 内核保护 | 无 (单地址空间) | MMU 隔离 |
| 用户堆 | 全局堆的一部分 | up_addrenv_vheap() 分配 |
在 FLAT 模式下,所有”任务”都共享同一个地址空间,类似于 FreeRTOS 的任务模型。在 KERNEL 模式下,每个用户进程拥有完整的独立地址空间,更像 Linux 的进程模型。
8.2 Identity Mapping 的妙用
NuttX KERNEL 模式对内核地址空间采用 identity mapping(虚拟地址 = 物理地址)。这个设计有两个好处:
- 内核驱动可以直接使用物理地址访问 MMIO 寄存器,不需要 ioremap
- MMU 使能/禁用的过渡更平滑——代码在 MMU 开启前后看到的地址相同
代价是内核物理内存被限制在低地址范围,用户空间被挤到高地址(0x80000000 起)。
8.3 IDLE 线程即初始化线程
nx_start 就是 CPU0 IDLE 线程的入口。这个设计避免了创建单独的”启动线程”,节省了内存和上下文切换开销。代价是 IDLE 线程在初始化期间不能做 IDLE 该做的事(清理延迟释放的内存等),但在初始化完成前系统也没有其他内存分配需要清理。
以上分析了整个启动流程中三个最核心的设计决策。下面给出本文涉及的所有源文件索引,方便读者按图索骥地深入源码。
9. 参考
| 文件 | 关键内容 |
|---|---|
arch/arm/src/armv7-a/arm_vectortab.S:60-73 |
异常向量表,复位向量 → __start |
arch/arm/src/armv7-a/arm_head.S:37-45 |
IDLE_STACK_BASE / IDLE_STACK_TOP 宏定义 |
arch/arm/src/armv7-a/arm_head.S:181-248 |
__start: SYS 模式进入、MMU/Cache 禁用、L1 页表清零 |
arch/arm/src/armv7-a/arm_head.S:285-321 |
.text 区域 L1 段映射 (1MB section entries) |
arch/arm/src/armv7-a/arm_head.S:377-389 |
TLB/分支预测器/I-Cache 无效化 |
arch/arm/src/armv7-a/arm_head.S:407-559 |
TTBR0/TTBCR/DACR/SCTLR 配置,MMU 开启 |
arch/arm/src/armv7-a/arm_head.S:660-708 |
.Lvstart: 栈设置,arm_boot() 调用,跳转 nx_start |
arch/arm/src/armv7-a/arm_head.S:719-755 |
arm_data_initialize: .bss 清零 |
arch/arm/src/qemu/chip.h:44-49 |
页表基址/大小宏定义 |
arch/arm/src/qemu/qemu_boot.c:77 |
arm_boot(): 平台 C 级初始化 |
arch/arm/src/qemu/qemu_memorymap.c:44-85 |
MMU 区域映射表 |
arch/arm/src/qemu/qemu_memorymap.h:43-63 |
QEMU virt 物理/虚拟内存布局 |
arch/arm/src/armv7-a/mmu.h:606-621 |
MMU 标志宏定义(MEMFLAGS, IOFLAGS) |
boards/arm/qemu/qemu-armv7a/scripts/dramboot.ld:26-137 |
链接脚本,MEMORY 和 SECTIONS 布局 |
boards/arm/qemu/qemu-armv7a/src/qemu_boardinit.c:66-115 |
板级初始化函数 (qemu_board_initialize, board_late_initialize) |
boards/arm/qemu/qemu-armv7a/src/qemu_bringup.c:161-211 |
板级 bringup(tmpfs/procfs 挂载,FDT 设备注册) |
sched/init/nx_start.c:95-198 |
全局调度器数据结构 (g_readytorun, g_idletcb[], g_nx_initstate) |
sched/init/nx_start.c:328-420 |
idle_task_initialize(): 为每个 CPU 创建 IDLE TCB |
sched/init/nx_start.c:430-480 |
idle_group_initialize(): IDLE 组初始化 |
sched/init/nx_start.c:502-772 |
nx_start(): OS 全部初始化编排(完整函数) |
sched/init/nx_bringup.c:297-391 |
nx_start_application(): 板级后期初始化 + 启动用户程序 |
sched/init/nx_bringup.c:436-456 |
nx_create_initthread(): 创建 AppBringUp 初始化线程 |
sched/init/nx_bringup.c:496-552 |
nx_bringup(): 系统 bring-up 完整函数 |
sched/task/task_start.c:68-108 |
nxtask_start(): 内核线程直接调用 vs 用户任务 up_task_start 分派 |
sched/task/task_spawn.c:46 |
task_spawn() 编译排除 (CONFIG_BUILD_KERNEL 下不可用) |
binfmt/binfmt_exec.c:193 |
exec_spawn(): 用户进程创建入口 |
binfmt/binfmt_execmodule.c:152 |
exec_module(): ELF 加载 + 地址空间创建 + TCB 初始化 |
arch/arm/src/common/arm_initialize.c:62-121 |
up_initialize(): 硬件驱动初始化编排 |
arch/arm/src/common/arm_allocateheap.c:155-180 |
up_allocate_kheap(): 内核堆边界计算 |
arch/arm/src/qemu/qemu_irq.c:105 |
up_irqinitialize(): GIC 中断控制器初始化 |
arch/arm/src/qemu/qemu_timer.c:35 |
up_timer_initialize(): ARM 架构定时器初始化 |
arch/arm/src/qemu/qemu_serial.c:45-62 |
arm_earlyserialinit() / arm_serialinit(): PL011 串口 |
libs/libc/sched/task_startup.c:58 |
nxtask_startup(): 用户空间任务入口 (C++ 初始化 + main) |
apps/system/nsh/nsh_main.c |
NSH shell 的 main 函数入口 |
10. 完整启动流程图