Nuttx - SMP
拆解 NuttX 如何将单核 RTOS 改造为对称多处理器操作系统——从 CPU 启动、任务分配、跨核 IPI、自旋锁到临界区的完整实现路径。
阅读指南: 本文回答以下问题:NuttX 如何在多核处理器上同时启动 4 个 CPU?一个就绪任务如何被分配到最合适的核心上执行?CPU 之间如何通过 IPI(核间中断)和自旋锁协同工作而不相互破坏数据?enter_critical_section() 在多核下发生了哪些根本性变化?读完后,你将能够从源码级别理解 NuttX SMP 的调度决策路径、核间通信机制和同步原语设计,并具备独立调试 SMP 竞态条件的能力。
1. 为什么需要 SMP?——单核假设的崩溃
NuttX 最初为一个假设设计:系统中只有 一个 CPU。在这个假设下,许多设计非常简洁:
- 只有一个
g_readytorun链表,链表头就是”当前正在运行的任务”; this_task()直接取g_readytorun.head,不需要知道自己在哪个 CPU 上;sched_lock()递增lockcount→ 禁止抢占,等于独占整个 CPU;enter_critical_section()关本地中断 → 临界区成立,因为没有别的 CPU 能碰数据。
当硬件变为 4 核 Cortex-A9(如 i.MX6 Quad),上述假设全部失效:
- 哪个任务是”当前任务”? 4 个 CPU 上同时运行着 4 个不同的任务。
- 关本地中断不够。 CPU0 关了中断,CPU1 仍然可能修改同一个内核数据结构。
sched_lock()不能阻止其他核上的任务运行。 只是阻止了当前 CPU 的抢占。
NuttX 官方设计文档 Documentation/implementation/smp.rst 列出了 SMP 的 7 大设计需求:
- 能够启动多个 CPU 并运行 NuttX
- 需要管理多个活跃任务的数据结构
- 需要能在其他 CPU 上调度任务
- 需要能修改在其他 CPU 上运行的任务
- 需要管理所有 CPU 上的临界区
- 需要自旋锁来阻塞所有 CPU
- 需要理解
sched_lock()等非标准操作在 SMP 下的语义变化
本文将逐一拆解这些需求的实现。**所有的源码引用基于 i.MX6 Quad (ARMv7-A, 4 核)**,CONFIG_SMP_NCPUS=4。
2. 多核下的数据结构变革
在深入调度算法之前,先理解数据结构的根本变化。这些结构是后续所有逻辑的基础。
2.1 g_readytorun:从”全部就绪”到”未分配任务池”
在单核 NuttX 中,g_readytorun 是一个按优先级排序的双向链表,包含所有就绪任务,链表头就是当前正在运行的任务,链表尾一定是 IDLE 任务。
在 SMP 下,g_readytorun 的语义发生了根本变化:
1 | // sched/sched/sched.h:170-188 |
SMP 下 g_readytorun 只包含尚未分配 CPU 且未在运行的任务。正在运行的任务不再存在于这个链表中——它们被搬到了新的数据结构 g_assignedtasks[] 中。
1 | 单核:g_readytorun = [Task A(运行)] -> [Task B] -> [Task C] -> [IDLE] |
下图可视化了 g_readytorun 和 g_assignedtasks[] 的关系:
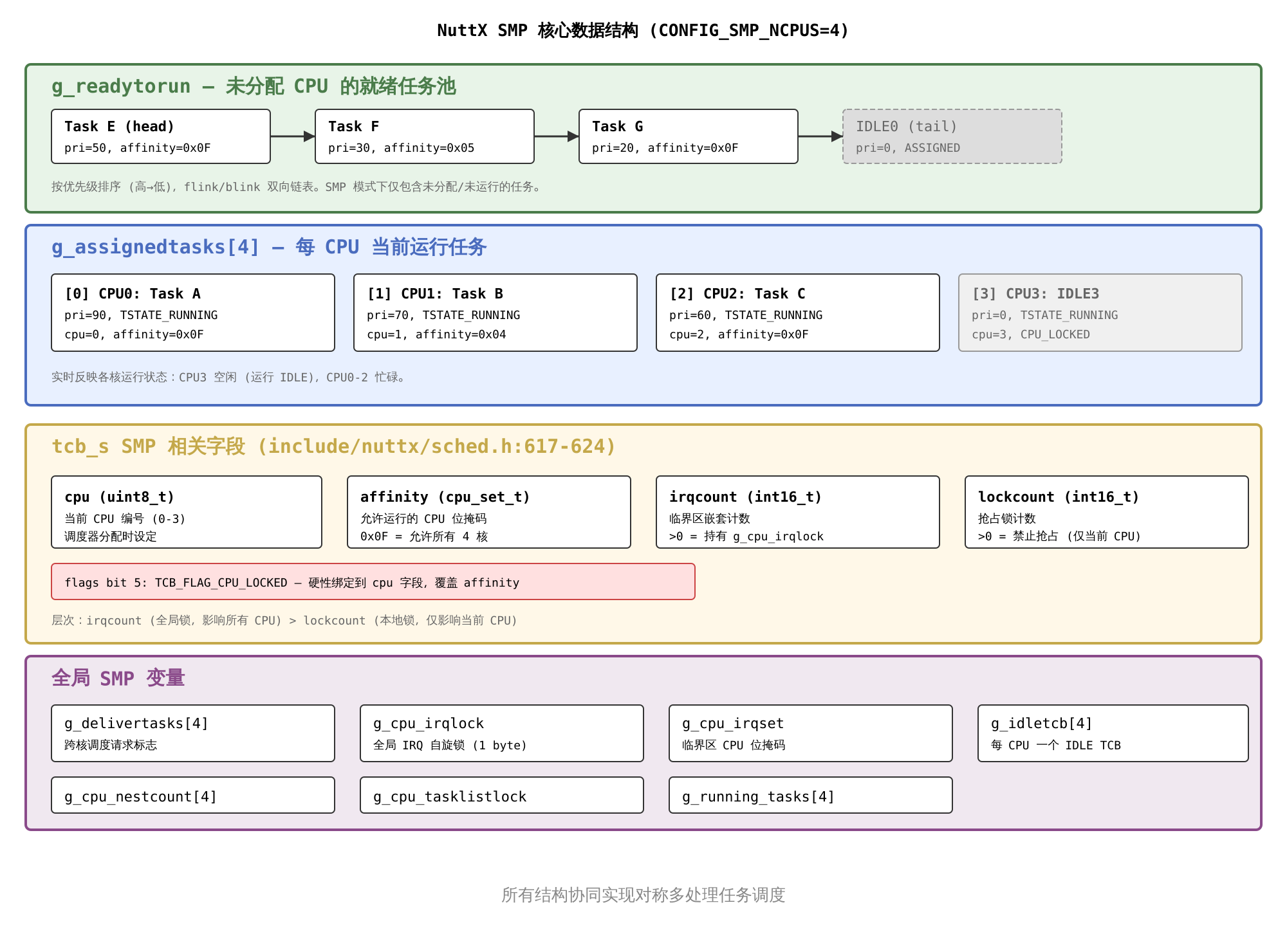
注:IDLE0(优先级 0)仍然保留在
g_readytorun尾部保持链表非空,但它已被分配给了 CPU0,其状态为TSTATE_TASK_ASSIGNED。
2.2 g_assignedtasks:每 CPU 的运行任务向量
与官方设计文档中设想的 dq_queue_t g_assignedtasks[CONFIG_SMP_NCPUS](每个 CPU 一个队列)不同,实际实现是一个更简洁的指针数组:
1 | // sched/init/nx_start.c:116 |
每个 CPU 只存储一个 TCB 指针——当前正在该 CPU 上执行的任务。非运行但已分配的就绪任务仍然放回 g_readytorun。
这是一个重要的简化:最初设计曾设想过每个 CPU 维护一个”已分配任务队列”,但最终实现选择了”当前运行任务指针 + 全局就绪池”的模式。这避免了对每个 CPU 维护优先级队列的复杂度。
2.3 TCB 的 SMP 字段
tcb_s 结构体(include/nuttx/sched.h:617-624)中新增了以下 SMP 相关字段:
1 | // include/nuttx/sched.h:617-624 |
关键字段解释:
| 字段 | 类型 | 含义 |
|---|---|---|
cpu |
uint8_t |
任务被分配到的 CPU 编号。调度器在任务就绪时设定 |
affinity |
cpu_set_t |
位掩码,限制任务只能运行在哪些 CPU 上。子线程继承父线程 |
flags (Bit 5) |
TCB_FLAG_CPU_LOCKED |
置位时 cpu 字段为权威值,覆盖 affinity。IDLE 任务始终置位 |
lockcount |
int16_t |
sched_lock() 递增,sched_unlock() 递减。>0 时禁止抢占 |
irqcount |
int16_t |
enter_critical_section() 递增。>0 时处于临界区,并持有全局 IRQ 自旋锁 |
TCB_FLAG_CPU_LOCKED 的定义(include/nuttx/sched.h:101):
1 |
当此标志置位时,任务只能在 tcb->cpu 指定的 CPU 上运行,调度器不会尝试将其迁移。
实例:IDLE 任务的 TCB 初始化值(i.MX6 Quad, CONFIG_SMP_NCPUS=4)
以 CPU0 的 IDLE 任务为例,初始化后的 TCB 关键字段值:
1 | tcb->pid = 0 // IDLE PID = CPU 编号 |
CPU0 和 CPU1-3 的 IDLE 任务唯一区别:
- CPU0:
start = nx_start,g_assignedtasks[0]已直接设为&g_idletcb[0] - CPU1-3:
start = nx_idle_trampoline,g_assignedtasks[i] = &g_idletcb[i]
与 Linux 的对比: Linux 的 task_struct 中有 thread_info->cpu 字段存储在栈的末端(通过 current_thread_info()->cpu 获取),还有 cpus_allowed(对应 NuttX 的 affinity)。NuttX 将这两个字段直接嵌入 TCB,避免了栈对齐的复杂度。
2.4 this_task() 和 current_task() 的多核版本
单核下 this_task() 等价于 g_readytorun.head。SMP 下必须根据当前 CPU 索引查找 g_assignedtasks[]:
1 | // sched/sched/sched.h:69-73 |
1 | // sched/sched/sched.h:371-393 — SMP 版本的 this_task() |
为什么需要关中断? this_cpu() 返回当前 CPU 编号,然后以此索引 g_assignedtasks[]。如果在这两步之间发生调度导致任务被迁移到另一个 CPU,就会读到错误的任务。关本地中断保证这个两步操作的原子性。
1 | // include/nuttx/sched.h:222-226 |
up_this_cpu() 在 ARMv7-A 上通过读取 CP15 协处理器的 MPIDR(Multiprocessor Affinity Register)寄存器实现,该寄存器包含当前 CPU 的硬件 ID。
2.5 g_delivertasks:跨核调度请求数组
单核下调度决策只在当前 CPU 上生效。多核下,CPU0 可能决定 CPU1 应该切换任务。这需要一个核间通信机制:
1 | // sched/init/nx_start.c:117 |
其中 task_deliver_e 枚举(sched/sched/sched.h:138-145):
1 | enum task_deliver_e |
这是 NuttX 的”任务交付协议”核心:当一个 CPU 决定另一个 CPU 应该重新调度时,它在 g_delivertasks[target] 中写入优先级级别,然后发送 IPI(核间中断)触发目标 CPU 执行调度。
实例:4 核系统中的典型 g_delivertasks 状态
1 | // CPU0 触发对 CPU3 的调度请求后: |
以上数据结构定义了 SMP 的”静态快照”。接下来我们看这些结构是如何被填充的——从只有 CPU0 活跃的启动时刻开始。
3. CPU 启动:从单核到多核的引导流程
3.1 为什么需要特殊的启动流程?
多核处理器的启动遵循不对称模型:上电后只有 CPU0(主核)开始执行 boot ROM,其余 CPU(次级核)处于复位状态。CPU0 需要完成 OS 初始化后,逐个释放次级核。这不同于 Linux 的 smp_init() / secondary_start_kernel(),但原理相同。
NuttX 官方文档 Documentation/implementation/smp.rst:311-328 描述了这一设计:
“I assume that initially, only one CPU is active. System initialization would then occur on that single thread. At the completion of the initialization of the OS, just before beginning normal multitasking, the additional CPUs would be started.”
3.2 IDLE 任务的创建
nx_start()(sched/init/nx_start.c)在系统初始化早期为每个 CPU 创建一个 IDLE 任务。详细流程在 idle_task_initialize()(第 328-420 行):
1 | // sched/init/nx_start.c:328-420 — IDLE 任务初始化 (关键 SMP 部分) |
对于 i.MX6 Quad,CONFIG_SMP_NCPUS=4,所以会创建 4 个 IDLE 任务:
- CPU0 IDLE (pid=0) — 入口点:
nx_start的尾部 - CPU1 IDLE (pid=1) — 入口点:
nx_idle_trampoline - CPU2 IDLE (pid=2) — 入口点:
nx_idle_trampoline - CPU3 IDLE (pid=3) — 入口点:
nx_idle_trampoline
为什么 lockcount=1? 初始化阶段调度器尚未完全就绪,必须先禁止抢占。最后在 CPU0 进入 IDLE 循环前调用 sched_unlock() 释放。
3.3 nx_smp_start():启动次级 CPU
CPU0 完成所有 OS 初始化后(内存、驱动、中断、文件系统、网络),在 nx_start() 第 734 行调用 nx_smp_start():
1 | // sched/init/nx_smpstart.c:118-142 |
这里的关键操作是 up_flush_dcache_all()。CPU0 在初始化期间修改了 g_assignedtasks[]、g_idletcb[] 等全局数据结构,这些修改可能在 CPU0 的 D-Cache 中尚未写回主存。如果次级 CPU 不经过 D-Cache 直接读取主存,将看到过期的数据。刷 D-Cache 保证核间数据一致性。
在 i.MX6 Quad 上,up_cpu_start() 的实现位于 arch/arm/src/armv7-a/arm_cpustart.c:112-129:
1 | int weak_function up_cpu_start(int cpu) |
ARM GICv2 使用 SGI(Software Generated Interrupt)来触发次级 CPU。SGI 编号定义如下:
1 | // arch/arm/src/armv7-a/gic.h:643-651 |
3.4 次级 CPU 的汇编入口
次级 CPU 被释放后从硬件复位向量开始执行,经过 boot ROM 后跳转到 NuttX 的汇编入口。以 ARMv7-A 为例(arch/arm/src/armv7-a/arm_cpuhead.S:85-112):
1 | __cpu1_start: @ CPU1 的入口标签 |
公共代码 .Lcpu_start(arm_cpuhead.S:192-394)执行:
- 关闭 MMU 和 Cache(清除 SCTLR 的 M/C/I 位)
- 无效化 TLB(
TLBIALLIS)、分支预测器(BPIALLIS)、I-Cache(ICIALLUIS) - 初始化 TTBR0/TTBR1 页表基址寄存器
- 配置域访问控制(DACR)
- 使能 MMU → 跳转到虚拟地址
.Lcpu_vstart
然后调用 C 函数 arm_cpu_boot(cpu),最终进入 nx_idle_trampoline()。
3.5 nx_idle_trampoline():次级 CPU 的”自旋等待-首次调度”
1 | // sched/init/nx_smpstart.c:68-93 |
OSINIT_IDLELOOP() 是 nx_start() 末尾设置的一个全局标志。次级 CPU 在这个 while 循环上自旋等待,直到 CPU0 完成所有初始化(包括启动 init 进程)进入 IDLE 循环后才释放。
以下是完整的 CPU 启动时序图:
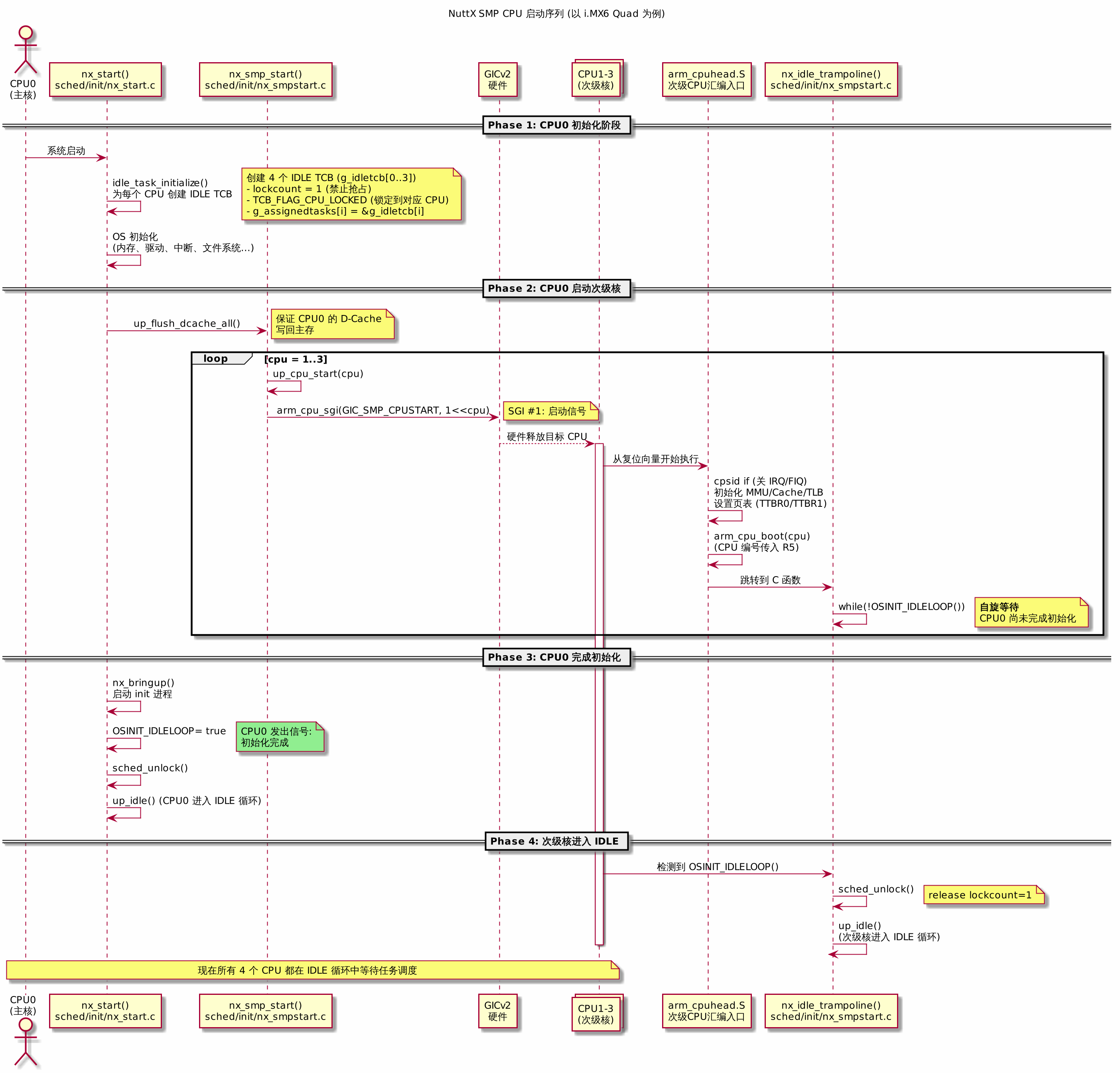
与 Linux 的对比: Linux 使用 cpu_up() → smp_ops.smp_boot_secondary() → 次级 CPU 执行 secondary_start_kernel(),其中包含一个自旋等待 cpu_startup_entry() 的准备过程。NuttX 的模式更简单:次级 CPU 直接跳转到 IDLE trampoline,等待 CPU0 完成初始化后释放调度锁。
所有 CPU 都启动后进入 IDLE 循环等待任务。那么当第一个非 IDLE 任务就绪时,NuttX 如何决定它该在哪个 CPU 上运行?答案在下一节。
4. 任务分配:CPU 选择算法
当一个任务变为就绪(例如信号量被释放、定时器到期、或新任务被创建),调度器需要决定两个问题:
- 目标 CPU 选哪个?——
nxsched_select_cpu() - 如何让目标 CPU 实际执行新任务?——
nxsched_add_readytorun()+nxsched_deliver_task()
4.1 nxsched_select_cpu():最低优先级启发式
1 | // sched/sched/sched.h:567-608 |
算法逻辑:
- 只考虑任务亲和性掩码允许的 CPU(
affinity位掩码) - 如果某 CPU 正在运行 IDLE 任务(优先级 0),立即选择它——不产生任何抢占开销
- 否则,选择当前运行任务优先级最低的 CPU——这最小化了抢占带来的开销
实例:i.MX6 Quad 上有 4 个 CPU,新任务 Task X (pri=80, affinity=所有CPU)
1 | CPU0: Task A, pri=90 ← 高优先级,不选 |
affinity 位掩码的每一位代表一个 CPU:
- CPU0: bit 0 = 1
- CPU1: bit 1 = 2
- CPU2: bit 2 = 4
- CPU3: bit 3 = 8
- 全允许:
0b1111= 0x0F
4.2 nxsched_add_readytorun():SMP 版本的就绪入队
1 | // sched/sched/sched_addreadytorun.c:253-277 |
完整执行流程(以 Task X, pri=80, CPU3 空闲为例):
- 确定目标 CPU:
TCB_FLAG_CPU_LOCKED未置位 → 调用nxsched_select_cpu(affinity)→ 返回 3(CPU3 空闲) - 将 Task X 以优先级顺序插入
g_readytorun - 设置
btcb->cpu = 3 - 比较:CPU3 正在运行 IDLE3 (pri=0),Task X (pri=80) → 80 > 0 → 触发
nxsched_deliver_task() nxsched_deliver_task决定是本地切换还是发送 IPI
4.3 nxsched_switch_running():实际执行任务替换
当目标 CPU 响应调度请求后,nxsched_switch_running() 执行实际的任务替换:
1 | // sched/sched/sched_addreadytorun.c:152-216 |
关键细节:
nxsched_islocked_tcb(rtcb)检查rtcb->lockcount > 0。如果当前任务通过sched_lock()禁止了抢占,不做任何切换,即使有更高优先级任务等待。- 亲和性检查:
CPU_ISSET(cpu, &btcb->affinity)确保任务允许在当前 CPU 上运行。 - CPU_LOCKED 覆盖:如果
TCB_FLAG_CPU_LOCKED置位,只接受btcb->cpu == cpu的精确匹配。 - 旧任务处理:非 IDLE 的旧任务被放回
g_readytorun等待下次调度;IDLE 不进入g_readytorun(它始终”属于”当前 CPU,状态设为TSTATE_TASK_ASSIGNED)。
上一节展示了任务如何被标记为目标 CPU 的任务。但”标记”不等于”执行”——如果目标 CPU 是远程核,还需要一个机制通知对方。这就是跨核 IPI 调度协议要解决的问题。
5. 跨核调度:IPI 与任务交付协议
5.1 为什么需要跨核调度?
单核系统中,调度决策和被调度任务的执行发生在同一 CPU 上。多核下出现了”调度者”与”执行者”分离的场景:
- CPU0 上的中断处理例程唤醒了一个高优先级任务
- 根据
nxsched_select_cpu()的决策,该任务应该运行在 CPU2 上 - 但 CPU2 不知道有更高优先级的任务就绪了——它可能正在运行一个低优先级任务甚至 IDLE
解决这个问题需要 IPI(Inter-Processor Interrupt,核间中断)——一个 CPU 向另一个 CPU 发送硬件中断信号。
5.2 nxsched_deliver_task():本地 vs 远程的分发逻辑
1 | // sched/sched/sched.h:541-565 |
逻辑分支:
- **
cpu == target_cpu**:目标任务就在当前 CPU 上(例如就绪任务的亲和性只允许当前 CPU)。直接调用nxsched_switch_running()执行本地上下文切换。 - **
cpu != target_cpu**:目标任务在远程 CPU 上。先将g_delivertasks[target_cpu]设为priority(告诉目标 CPU “你要切换到什么级别的任务”),然后发送 IPI。
g_delivertasks[target_cpu] != priority 这个条件起到了去重作用:如果目标 CPU 已经有一个相同或更高优先级的调度请求待处理,就不再重复发送 IPI,减少了不必要的核间中断。
5.3 up_send_smp_sched():架构特定的 IPI 发送
不同架构使用不同的硬件机制发送 IPI。ARMv7-A 的实现(arch/arm/src/armv7-a/arm_smpcall.c:96-101):
1 | int up_send_smp_sched(int cpu) |
arm_cpu_sgi() 写入 GICv2 的 GICD_SGIR 寄存器(Software Generated Interrupt Register),指定 SGI 编号(3 = GIC_SMP_SCHED)和目标 CPU 位掩码。
各架构的 IPI 机制对比:
1 | ARMv7-A/ARMv7-R: GICv2 SGI (SGI #3 = GIC_SMP_SCHED) |
RISC-V 的 SMP 处理有一个有趣的区别——它的 IPI 处理函数同时负责调度和跨核函数调用,并在中断处理函数内部显式保存和恢复上下文(arch/risc-v/src/common/riscv_smpcall.c:60-78):
1 | int riscv_smp_call_handler(int irq, void *c, void *arg) |
ARM 的实现则将三个功能(CPU 启动、调度触发、函数调用)分配给了三个独立的 SGI 处理函数。
5.4 nxsched_process_delivered():IPI 中断处理
目标 CPU 收到 IPI 后,进入 arm_smp_sched_handler()(或等效的架构处理函数),调用 nxsched_process_delivered():
1 | // sched/sched/sched_process_delivered.c:63-120 |
故障转发机制(第 90-113 行): 如果 nxsched_switch_running() 失败(通常因为当前任务通过 sched_lock() 禁止了抢占),该函数不会丢弃调度请求。它检查 g_readytorun 头部的最高优先级任务,重新选择一个目标 CPU,并将请求转发给另一个 CPU。这保证了调度延迟的最小化。
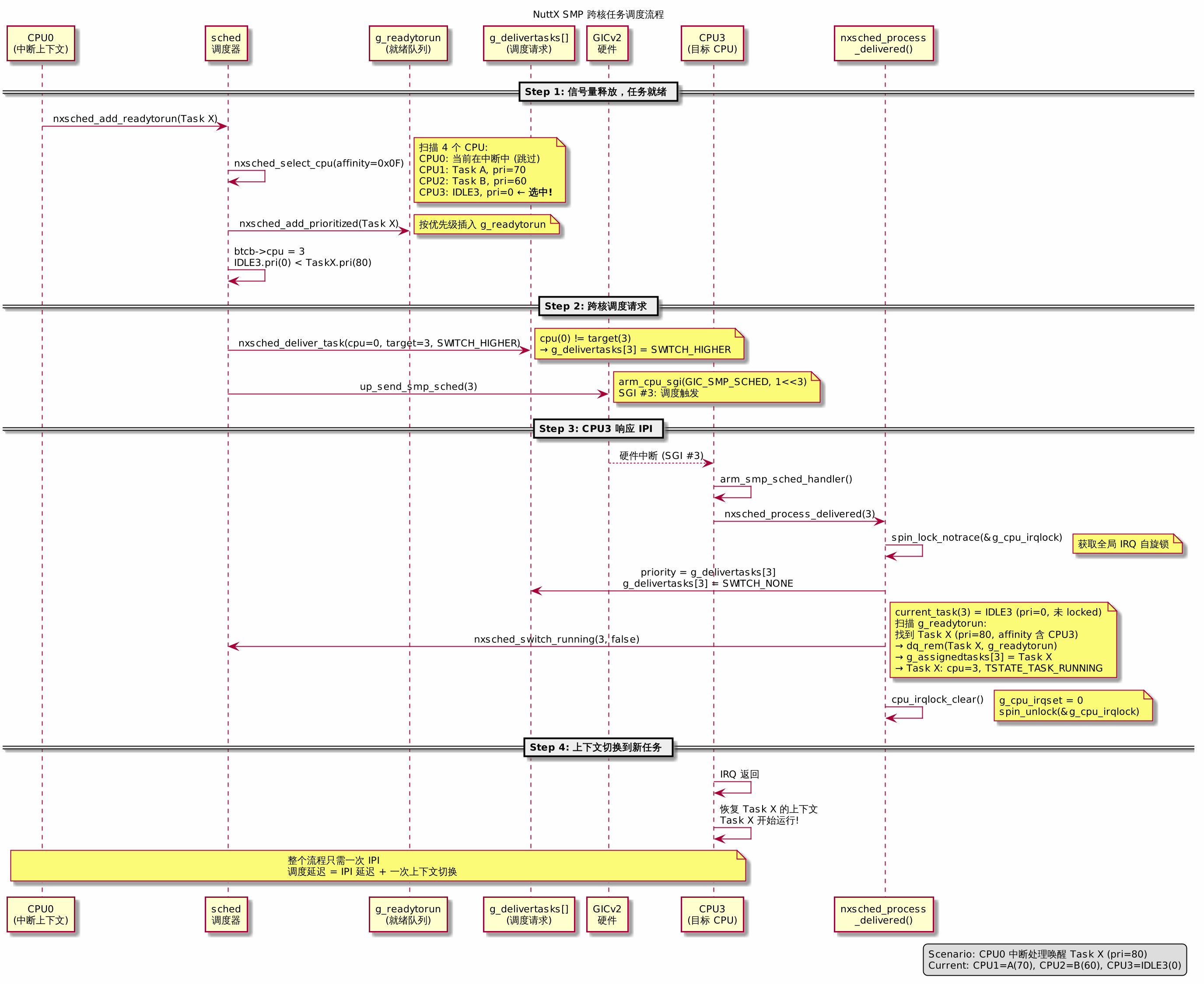
完整调度决策路径(具体实例):
1 | 场景:CPU0 上的中断例程释放了一个信号量,唤醒 Task X (pri=80, affinity=0x0F) |
下图展示了跨核调度中各组件的交互:
跨核调度解决了”让远程 CPU 执行任务”的问题,但没有解决”多个 CPU 同时修改共享数据”的问题。IPI 通知本身需要原子性保证——不能多个 CPU 同时写入 g_delivertasks[]。这就需要自旋锁。
6. 自旋锁:SMP 核心同步原语
6.1 为什么需要自旋锁?
在单核 NuttX 中,enter_critical_section() 关本地中断就足以保护内核数据结构,因为没有其他 CPU 会同时访问。在多核下,关本地中断只能阻止当前 CPU 上的上下文切换和中断——CPU1 仍然可以自由地修改同一数据结构。
自旋锁(spinlock)通过一个原子变量和一个忙等循环,确保同一时刻只有一个 CPU 能持有锁并访问受保护资源。
6.2 up_testset():硬件原子操作
自旋锁的核心是 up_testset()——一个原子的”读取-修改-写入”操作。在 ARMv7-A 上使用 LDREXB/STREXB 指令实现(arch/arm/include/spinlock.h:102-123):
1 | static inline_function spinlock_t up_testset(volatile spinlock_t *lock) |
ARM 的 LDREX/STREX 机制: ARM 使用”独占监视器”(exclusive monitor)。LDREXB 加载一个字节的同时在硬件中标记该地址为”独占”。STREXB 只有在独占标记仍然有效时才写入,否则返回非零表示失败(另一个 CPU 在此期间修改了该地址)。这就是 LL/SC(Load-Linked/Store-Conditional)模式。
spinlock_t 在 ARM 上是 uint8_t(1 字节),SP_UNLOCKED=0,SP_LOCKED=1。
不同架构的 up_testset() 对比:
| 架构 | spinlock_t | 原子指令 | 特点 |
|---|---|---|---|
| ARM (32-bit) | uint8_t |
LDREXB/STREXB |
字节粒度,DMB 屏障 |
| ARM64 | uint64_t |
LDAXR/STXR |
64-bit,带 acquire 语义 |
| RISC-V | uintptr_t |
AMOSWAP.W/D |
原子交换,fence 屏障 |
| Xtensa | uint32_t |
S32C1I |
Store Conditional Immediate |
| x86_64 | uintptr_t |
XCHG |
隐含 LOCK 前缀 |
| SPARC | uint32_t |
CASA |
Compare and Swap Alternative |
| SIM | uint8_t |
atomic_exchange |
C11 stdatomic |
6.3 spin_lock():忙等获取锁
1 | // include/nuttx/spinlock.h:183-197 |
up_testset()返回旧值:SP_UNLOCKED (0) → 成功获取锁,退出循环;SP_LOCKED (1) → 锁被其他 CPU 持有,继续循环`UP_WFE()(Wait For Event) 让 CPU 进入低功耗等待状态,直到收到 SEV (Send Event) 信号。spin_unlock()会发送 SEV 唤醒等待者UP_DSB()/UP_DMB()是内存屏障,确保锁变量的读写不会被 CPU 的乱序执行重排
6.4 全局 IRQ 自旋锁:g_cpu_irqlock
NuttX 定义了一个全局自旋锁 g_cpu_irqlock(sched/irq/irq_csection.c:62),用于保护所有进入临界区的代码路径:
1 | volatile spinlock_t g_cpu_irqlock = SP_UNLOCKED; |
g_cpu_irqset 是一个位掩码,每一位代表一个 CPU 当前是否在临界区内。g_cpu_nestcount[] 处理中断处理函数中对 enter_critical_section() 的嵌套调用。
6.5 Ticket Spinlock
NuttX 还支持 Ticket Spinlock(CONFIG_TICKET_SPINLOCK),解决了普通自旋锁的公平性问题:
1 | // include/nuttx/spinlock_type.h:57-66 |
1 | // include/nuttx/spinlock.h:185-188 (ticket 版本) |
与银行排队叫号类似:每个 CPU 先领取一个递增的号码(next),然后等待 owner 等于自己的号码。这保证了 FIFO 公平性——先请求的 CPU 先获得锁,避免了某些 CPU 长时间”饥饿”。
自旋锁是底层原语。enter_critical_section() 是建立在自旋锁之上的高层封装——它还必须处理中断上下文与任务上下文的差异、嵌套调用、以及与 NuttX 原有的抢占控制协同工作。本节剖析这个复杂的组合逻辑。
7. 临界区:enter_critical_section 的多核重构
7.1 单核 vs 多核的语义变化
在单核 NuttX 中,临界区的语义很简单:关本地中断 → 临界区成立。因为只有一个 CPU,关中断就消除了所有竞争。
多核下的语义必须扩展:关本地中断 + 获取全局 IRQ 自旋锁。关中断防止当前 CPU 上的上下文切换和中断重入;全局自旋锁防止其他 CPU 同时进入临界区。
7.2 enter_critical_section_notrace():双路径处理
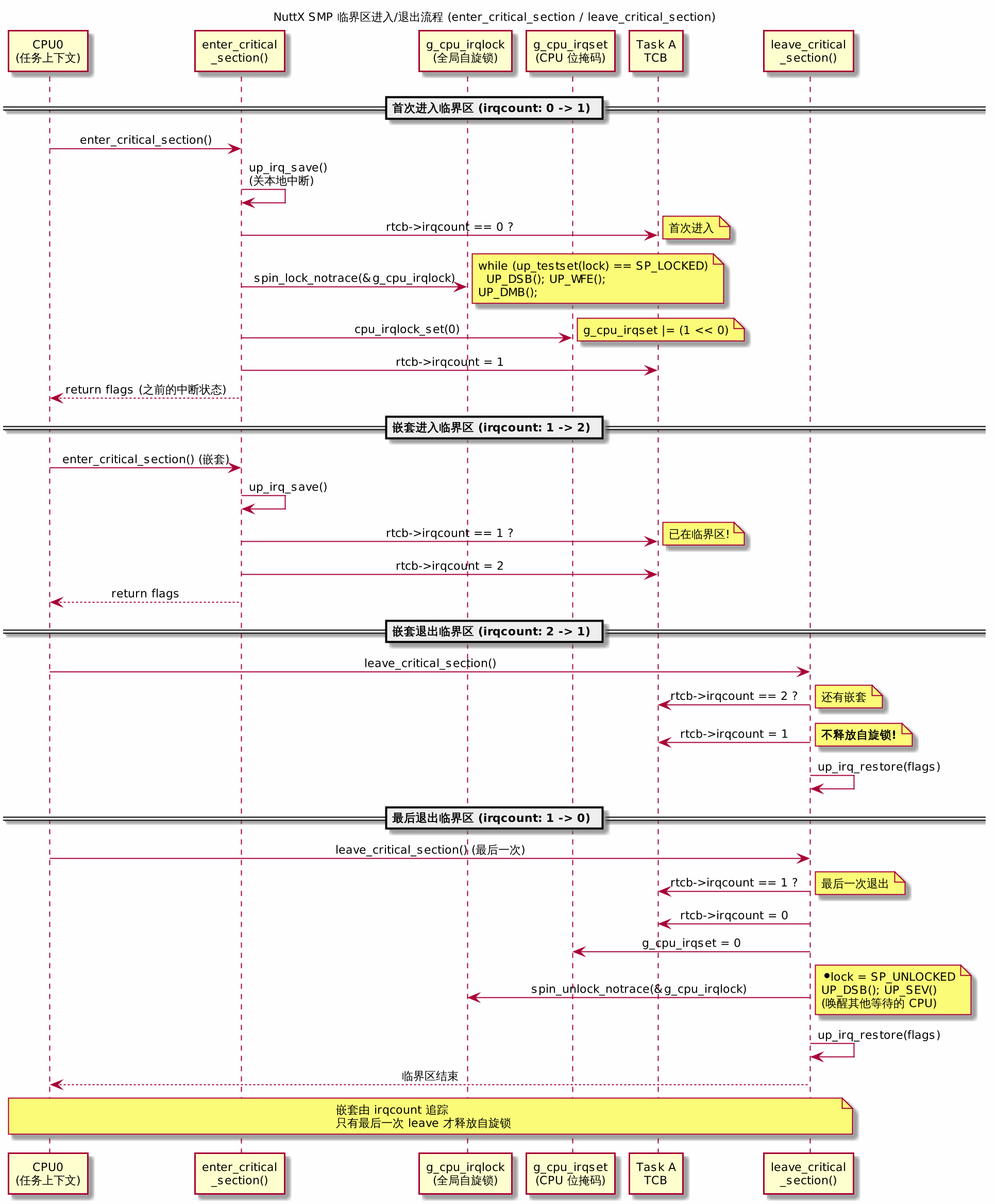
自旋锁的状态转换如下图所示。状态机有两个核心状态——SP_UNLOCKED (0) 表示锁空闲,任何 CPU 都可以通过 up_testset() 原子操作将其翻转为 SP_LOCKED (1)。当 CPU0 持有锁时,g_cpu_irqset 的第 0 位被置位,标记”CPU0 正在临界区”。其他 CPU 尝试获取锁时会进入自旋循环:反复调用 up_testset() 直到其返回 SP_UNLOCKED,每次失败后执行 UP_WFE() 进入低功耗等待。当 CPU0 调用 cpu_irqlock_clear() 释放锁时,g_cpu_irqset 被清零,spin_unlock() 发送 SEV 事件唤醒等待者。

这是 NuttX SMP 中最复杂的同步逻辑之一(sched/irq/irq_csection.c:92-254)。它必须处理两种调用场景:
路径 A:从中断处理函数调用(up_interrupt_context() 为真)
1 | // sched/irq/irq_csection.c:117-193 — 中断上下文路径 |
路径 B:从任务上下文调用(正常内核代码)
1 | // sched/irq/irq_csection.c:195-248 — 任务上下文路径 |
嵌套支持: irqcount(任务上下文)和 g_cpu_nestcount[cpu](中断上下文)分别支持各自路径的嵌套。例如:
1 | Task A (pri=80) 调用 enter_critical_section() |
7.3 leave_critical_section_notrace():安全退出
1 | // sched/irq/irq_csection.c:334-433 — 退出的任务路径 |
cpu_irqlock_clear() 宏(include/nuttx/irq.h:99-107):
1 |
注意: cpu_irqlock_clear() 将 g_cpu_irqset 整体清零(而非仅清除当前 CPU 的位),因为它假设同一时刻只有一个 CPU 能释放锁。这种设计在嵌套使用中依赖于 irqcount 来保证正确性。
7.4 临界区对抢占的副作用
完整的临界区进入/退出时序图:
进入临界区不仅关中断,还会修改抢占控制行为。NuttX 官方文档 Documentation/implementation/smp.rst:742-776 指出:
“The basic result of this modification is that new tasks are not permitted to be started or resumed if:
- Pre-emption is disabled, OR
- Some other CPU other than the current CPU is in a critical section.”
这意味着:如果 CPU0 处于临界区,CPU1 不能启动新任务或恢复已暂停的任务——即使 CPU1 自身的抢占是开启的。这是因为临界区持有 g_cpu_irqlock,而任务启动/恢复的逻辑通常也需要进入临界区。当 CPU1 尝试获取 g_cpu_irqlock 时,它会被阻塞在自旋锁上。
8. sched_lock / sched_unlock:禁止抢占的多核语义
前几章讨论了临界区如何通过全局自旋锁保护跨核共享数据。但 NuttX 还有另一个更低层级的保护机制——sched_lock()。理解它在 SMP 下的变化,需要先回答一个基础问题:为什么单核的”禁止抢占 == 独占 CPU”在多核下不再成立?
因为 SMP 下有 N 个 CPU。sched_lock() 只递增当前任务的 lockcount,而 lockcount 是 per-TCB 的字段。当 nxsched_switch_running() 检查 nxsched_islocked_tcb(rtcb) 时,它只阻止当前 CPU 上的任务替换——其他 3 个 CPU 完全不受影响。这与 enter_critical_section() 形成对比:后者持有全局自旋锁 g_cpu_irqlock,确实能影响所有 CPU。
8.1 sched_lock():仅限当前 CPU
1 | // sched/sched/sched_lock.c:67-99 |
sched_lock() 在多核下的语义是 仅禁止当前 CPU 上当前任务的抢占。它不阻止其他 CPU 上的任务继续运行,也不阻止其他 CPU 上的任务被抢占。
实例:4 核系统中 sched_lock() 的影响范围
1 | CPU0: Task A 调用 sched_lock() → rtcb->lockcount = 1 |
这与单核有本质区别:单核下 sched_lock() 的效果等同于”此任务暂时独占 CPU”;多核下,它只意味着”此任务不会被当前 CPU 上的其他任务抢占”,但其他 CPU 上的活动完全不受影响。
8.2 sched_unlock():检查 g_readytorun 而非 g_pendingtasks
1 | // sched/sched/sched_unlock.c:73-102 — SMP 无关健路径 |
单核 NuttX 中,sched_lock() 期间到达的高优先级任务被放入 g_pendingtasks 列表,sched_unlock() 时合并回 g_readytorun。
SMP 下**没有 g_pendingtasks**。这是因为 nxsched_add_readytorun() 可以直接将任务放入 g_readytorun 并在另一个 CPU 上执行调度决策,不需要”暂存”机制。当 sched_unlock() 释放时,只需检查 g_readytorun 头部是否有比当前任务更高优先级的任务。
sched_lock() 和前文的临界区机制共同构成了 NuttX 的并发控制体系。最后我们看一个面向应用的 SMP 特性——CPU 亲和性,它让用户能显式指定任务可运行的 CPU 集合。
9. 线程亲和性 (Affinity)
9.1 为什么需要 CPU 亲和性?
SMP 系统默认的任务调度策略是”任意核可用”——nxsched_select_cpu() 在亲和性掩码允许的 CPU 中自由选择。但有些场景下,允许任务在 CPU 之间迁移是有害的:
- Cache 亲和性:任务在 CPU0 上运行一段时间后,其代码和数据被填充到 CPU0 的 L1/L2 Cache 中。迁移到 CPU1 意味着 Cache 冷启动——所有数据需要从主存重新加载,可能导致显著的性能波动。
- 实时隔离:在混合负载系统中,可能需要将实时任务固定到特定 CPU,确保它们不受其他时间共享任务的干扰。
- 设备亲和性:某些外设的中断只能路由到特定 CPU(例如 GICv2 的 SPI 中断可配置亲和性)。处理该中断的任务最好运行在同一 CPU 上。
NuttX 通过 tcb->affinity 字段实现了 CPU 亲和性机制,语义与 Linux 的 sched_setaffinity() 兼容。
9.2 默认行为
默认情况下,任务可以在任何 CPU 上运行:
1 | // sched/task/task_setup.c:226-234 |
如果从未显式设置亲和性,affinity 在初始化时被设为 CONFIG_SMP_DEFAULT_CPUSET & SCHED_ALL_CPUS(即允许所有 CPU)。
9.3 sched_setaffinity / sched_getaffinity
1 | // sched/sched/sched_setaffinity.c:74-156 |
如果任务当前 CPU 不在新的亲和性掩码中怎么办? NuttX 的策略是调用 nxsched_set_priority() 将其重新设置为相同的优先级。这会触发调度器将该任务从当前队列中移除并重新入队,在新的入队过程中,nxsched_select_cpu() 会基于新的 affinity 选择一个合适的 CPU。
9.4 TCB_FLAG_CPU_LOCKED
此标志表示任务被硬性绑定到特定 CPU。IDLE 任务始终设置了此标志(因为每个 CPU 有自己专用的 IDLE 任务),某些内核操作也会临时设置它以防止竞态条件。
9.5 与 Linux 的对比
Linux 使用 sched_setaffinity()(POSIX 标准)和 cpusets(cgroup 机制)。NuttX 在 POSIX 语义上基本兼容,但实现更简单:没有 cgroup 层级,亲和性直接存储在 TCB 中且仅为 CPU 级别的位掩码。
10. 关键要点总结
数据结构分层:NuttX SMP 引入了
g_assignedtasks[](每 CPU 当前运行任务指针)和g_delivertasks[](跨核调度请求数组),将单核g_readytorun的职责拆分为”未分配任务池”和”每 CPU 运行任务”两层。CPU 选择启发式:
nxsched_select_cpu()优先选择空闲 CPU(运行 IDLE 任务的),其次选择运行最低优先级任务的 CPU。该算法受任务亲和性掩码和TCB_FLAG_CPU_LOCKED约束。跨核调度协议:调度请求通过
nxsched_deliver_task()写入g_delivertasks[target],然后发送架构特定的 IPI(GICv2 SGI、RISC-V IPI、POSIX signal 等)。目标 CPU 在 IPI 处理函数中调用nxsched_process_delivered()完成实际调度。切换失败时自动转发给其他 CPU。全局自旋锁 + 位掩码:
g_cpu_irqlock是唯一保护临界区的全局自旋锁。g_cpu_irqset位掩码跟踪哪些 CPU 正在临界区内,支持非对称的持有者追踪。g_cpu_nestcount[]和irqcount分别处理中断上下文和任务上下文的嵌套。锁层次结构:
irqcount(全局临界区) >lockcount(本地抢占禁用)。sched_lock()不影响其他 CPU,而enter_critical_section()通过全局自旋锁影响所有 CPU。SGI 分离设计(ARM):CPU 启动(SGI1)、跨核函数调用(SGI2)、调度触发(SGI3)使用三个不同的 SGI 编号,各自有独立的处理函数。RISC-V 则合并到一个统一的处理函数中。
无 g_pendingtasks:SMP 下不存在待处理任务队列。任务就绪时直接进入
g_readytorun,调度决策可以在任何 CPU 上触发其他 CPU 的调度。
11. 参考资料
| 文件 | 内容 |
|---|---|
Documentation/implementation/smp.rst |
SMP 官方设计文档(872 行),包含最初的设计规格 |
Documentation/reference/os/smp.rst |
SMP API 参考文档(99 行) |
sched/init/nx_smpstart.c:68-142 |
nx_idle_trampoline() 和 nx_smp_start() |
sched/init/nx_start.c:328-420 |
idle_task_initialize() 创建每 CPU 的 IDLE TCB |
include/nuttx/sched.h:222-226 |
this_cpu() 宏定义 |
sched/sched/sched.h:69-73 |
current_task() 宏定义 |
sched/sched/sched.h:138-145 |
task_deliver_e 枚举(调度请求类型) |
sched/init/nx_start.c:116-117 |
g_assignedtasks[] 和 g_delivertasks[] 声明 |
sched/sched/sched.h:170-188 |
g_readytorun SMP 语义设计注释 |
sched/sched/sched.h:367-393 |
this_task() SMP 版本实现 |
sched/sched/sched.h:541-565 |
nxsched_deliver_task() 跨核调度分发 |
sched/sched/sched.h:567-608 |
nxsched_select_cpu() CPU 选择算法 |
sched/sched/sched_addreadytorun.c:152-277 |
nxsched_switch_running() 和 SMP 版 nxsched_add_readytorun() |
sched/sched/sched_process_delivered.c:63-120 |
nxsched_process_delivered() IPI 中断处理 |
sched/irq/irq_csection.c:57-483 |
enter_critical_section_notrace() 和 leave_critical_section_notrace() |
include/nuttx/sched.h:617-624 |
TCB 的 SMP 字段定义 |
include/nuttx/sched.h:101 |
TCB_FLAG_CPU_LOCKED 标志定义 |
include/nuttx/spinlock.h:183-197 |
spin_lock_notrace() 自旋锁获取 |
include/nuttx/spinlock_type.h:52-66 |
spinlock_t 和 ticket spinlock 类型定义 |
include/nuttx/irq.h:99-107 |
cpu_irqlock_clear() 宏 |
arch/arm/include/spinlock.h:102-123 |
ARM up_testset() — LDREXB/STREXB |
arch/arm/src/armv7-a/gic.h:643-651 |
GICv2 SGI 编号定义 |
arch/arm/src/armv7-a/arm_cpuhead.S:85-459 |
ARMv7-A 次级 CPU 汇编启动代码 |
arch/arm/src/armv7-a/arm_cpustart.c:112-129 |
up_cpu_start() ARMv7-A |
arch/arm/src/armv7-a/arm_smpcall.c:71-120 |
arm_smp_sched_handler 和 up_send_smp_sched |
sched/sched/sched_lock.c:67-99 |
sched_lock() |
sched/sched/sched_unlock.c:57-179 |
sched_unlock() SMP 路径 |
sched/sched/sched_setaffinity.c:74-156 |
nxsched_set_affinity() |
sched/task/task_setup.c:226-234 |
nxtask_inherit_affinity() |
sched/sched/sched_smp.c:53-360 |
SMP 跨核函数调用基础设施 |
arch/risc-v/src/common/riscv_smpcall.c:60-78 |
RISC-V SMP 统一处理和上下文保存/恢复 |