Nuttx - IPC
进程 A 怎么把一条带优先级的消息发给进程 B?共享内存又为什么能做到零拷贝?本文从信号量到消息队列、从管道到共享内存,用源码回答每种 IPC 的内核实现——不只看 API,看完数据结构、阻塞队列和 MMU 映射。
本文回答以下问题:NuttX 提供了哪些 IPC 机制,各自适用什么场景?消息队列如何实现带优先级的消息排序和阻塞等待?共享内存在 KERNEL 模式下如何通过 MMU 将同一物理页映射到多个进程?管道的环形缓冲区如何实现读写阻塞?读完后,你将能够选择合适的 IPC 机制,并从源码级别理解其内核实现。
1. 开篇:为什么需要多种 IPC 机制?
在 KERNEL 模式下,每个进程有独立的虚拟地址空间——进程 A 的指针对进程 B 毫无意义。进程间要通信,必须通过内核提供的受控通道。不同场景需要不同特征的通道:
| 需求 | 适合的 IPC |
|---|---|
| 互斥访问共享资源 | 信号量 / 互斥锁 |
| 传递结构化消息(带优先级) | 消息队列 |
| 高性能大数据共享(零拷贝) | 共享内存 |
| 流式字节数据传递 | 管道 / FIFO |
| 异步通知 | 信号(已在前文覆盖) |
NuttX 实现了 POSIX 标准(IEEE Std 1003.1)定义的全部 IPC 机制。NuttX 官方文档(https://nuttx.apache.org/docs/latest/reference/user/index.html)提供了各 API 的用户手册。本文先概览各机制的使用方式,再深入消息队列、共享内存和管道的内核实现。
2. IPC 机制使用概览
以下代码示例为用户应用层代码(非内核源码),展示各 IPC 机制的标准 POSIX API 用法。
2.1 信号量(Semaphore)
1 |
|
NuttX 信号量支持优先级继承(已在调度博客中讲解),阻塞的任务按优先级排序在 g_waitingforsemaphore 链表中。
2.2 互斥锁(Mutex)
互斥锁用于同一进程内的线程间互斥,不支持跨进程共享。NuttX 的 mutex 接受 PTHREAD_PROCESS_SHARED 属性但内部忽略它——该属性存在是为了 POSIX 兼容性,不改变实际行为。
1 |
|
NuttX 的 mutex 在内部基于信号量实现(sched/mutex/),增加了所有权检查(按 PID 判断)、递归计数(PTHREAD_MUTEX_RECURSIVE)和优先级继承。
如果需要在不同进程间做互斥同步,请用命名信号量
sem_open()——它是 NuttX 官方支持的跨进程 IPC 机制。
2.3 消息队列(Message Queue)
1 |
|
2.4 共享内存(Shared Memory)
1 |
|
注意:共享内存仅在 CONFIG_BUILD_KERNEL 模式下可用——它需要 MMU 和地址环境支持。
2.5 管道与 FIFO
1 |
|
概览完毕。下面深入消息队列的内核实现。
3. 深入:消息队列内核实现
消息队列提供三个关键特性:消息边界保持(每条消息完整交付,不会像管道那样被截断)、优先级排序(紧急消息可以插队)、内核托管(发送方不需要等接收方准备好)。
本章将逐一回答四个核心问题:
mq_open做了什么?——如何通过 VFS inode 创建和查找消息队列- 用户空间怎么到内核空间?——SVC 系统调用从触发到分派的完整链路
- 消息发送和接收怎么实现?——
mq_send/mq_receive的逐步骤分析- 如何管理阻塞与唤醒?——优先级等待队列 + 超时看门狗的协作机制
3.1 核心数据结构
消息队列由三层数据结构组成:消息节点(mqueue_msg_s)存储单条消息;队列本体(mqueue_inode_s)管理消息链表和容量;公共头部(mqueue_cmn_s)管理阻塞任务。mqueue_inode_s 内嵌 mqueue_cmn_s,而 mqueue_cmn_s 的两个 dq_queue_t 头各自链接着按优先级排序的 TCB。mqueue_inode_s 作为 inode->i_private 挂在 VFS 中,是内核操作消息队列的唯一入口。
下图展示了这些结构体的嵌套关系、字段布局以及”通过 VFS inode 找到 msgq → 通过 waitfornotempty/waitfornotfull 管理阻塞 TCB → 通过 msglist 存取消息”的完整数据流:
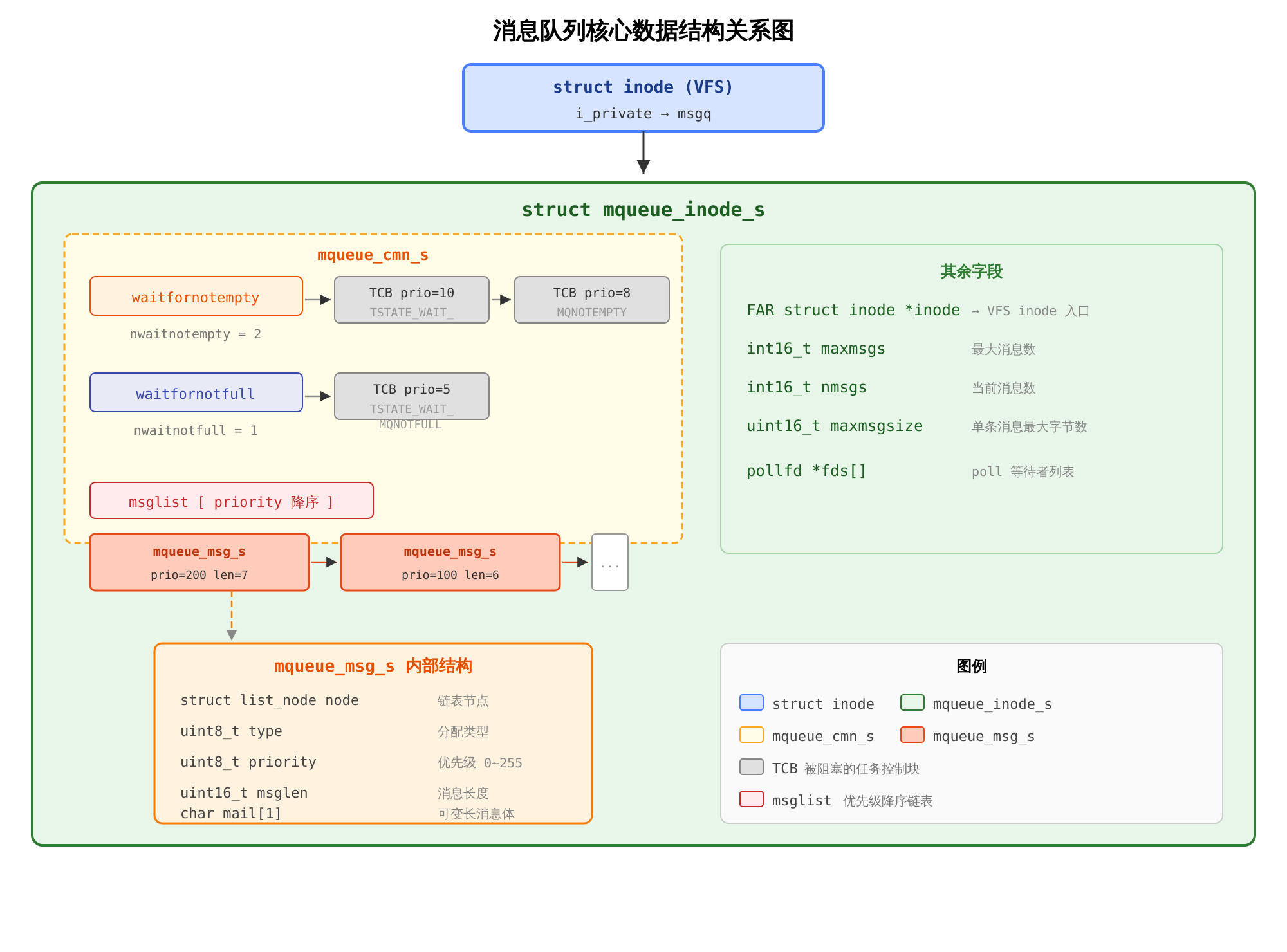
文件:sched/mqueue/mqueue.h:68-79
1 | struct mqueue_msg_s |
文件:include/nuttx/mqueue.h:103-131
1 | struct mqueue_cmn_s |
消息链表 msglist 始终按优先级降序排列(高优先级在前),mq_receive() 从链表头取即可得到最高优先级消息——O(1)取出。
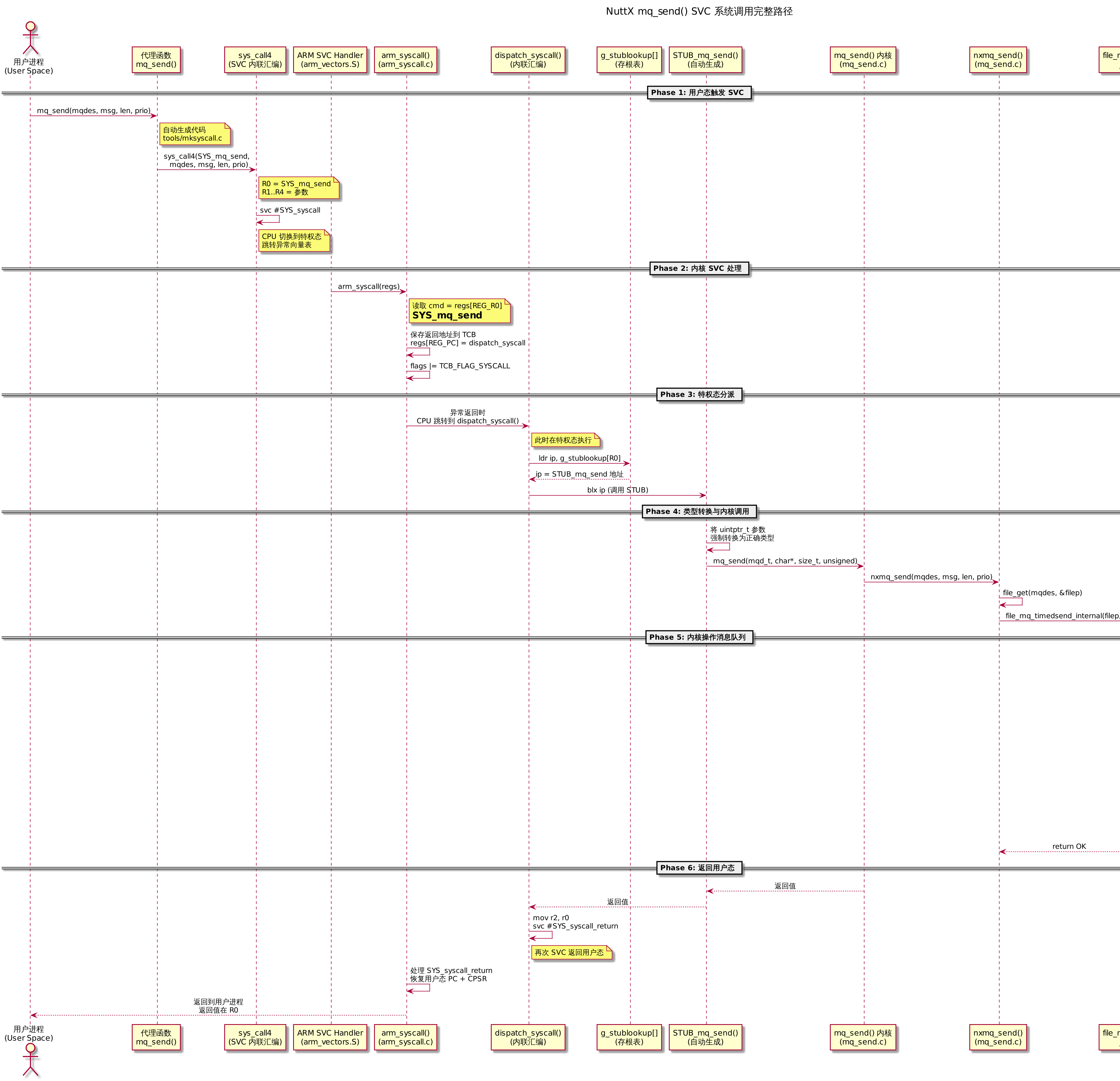
3.2 从用户空间到内核空间:SVC 系统调用路径
在 KERNEL 或 PROTECTED 构建模式下,用户进程运行在非特权态。mq_open、mq_send、mq_receive 等 POSIX API 由 tools/mksyscall.c 自动生成代理函数,通过 sys_call4 宏触发 svc 指令陷入内核。内核侧的 arm_syscall() 根据系统调用号查 g_stublookup[] 表,找到对应的 STUB 函数做类型转换后调用真正的内核实现。
完整调用链路(以 mq_send 为例):
1 | 用户进程 mq_send() |
下图展示了从用户态到内核态的完整桥接过程:
3.3 mq_open():消息队列的创建与打开
mq_open 的核心工作是:将用户给定的名字(如 "/myqueue")映射到 VFS 中的一个 inode,该 inode 的类型为消息队列(FSNODEFLAG_TYPE_MQUEUE),其 i_private 指向一个 mqueue_inode_s 实例。
完整流程(文件:fs/mqueue/mq_open.c:160-344,函数 file_mq_vopen):
1 | static int file_mq_vopen(FAR struct file *mq, FAR const char *mq_name, |
Step 6:分配 fd。file_mq_vopen 返回后,调用方 nxmq_vopen(mq_open.c:346-374)通过 file_dup() 为这个 struct file 分配用户态文件描述符 fd,返回给用户。因此 mq_open 的返回值 mqd_t 本质上就是一个 fd(整数)。
小结:mq_open 做了五件事:
- 拼接完整 VFS 路径(
CONFIG_FS_MQUEUE_VFS_PATH "/" name) - 在 VFS 中查找或创建 inode
- 分配
mqueue_inode_s,初始化maxmsgs、maxmsgsize和阻塞队列 - 将
msgq绑定到inode->i_private - 返回 fd 给用户
3.4 消息发送:mq_send() 完整链路
一条消息从用户进程到达内核消息队列,经历系统调用(3.2 节)后的内核执行路径如下。
内核入口(文件:sched/mqueue/mq_send.c:686-746):
从 SYS_syscall 路径进来后,mq_send() 本身只做取消点标记和错误码包装:
1 | int mq_send(mqd_t mqdes, FAR const char *msg, size_t msglen, unsigned int prio) |
nxmq_send() 通过 file_get(mqdes, &filep) 将 fd 转换为 struct file *,再调用核心函数 file_mq_timedsend_internal()。
核心发送逻辑(文件:sched/mqueue/mq_send.c:274-370,函数 file_mq_timedsend_internal):
1 | static int file_mq_timedsend_internal(FAR struct file *mq, |
优先级插入(文件:sched/mqueue/mq_send.c:206-240,nxmq_add_queue):
1 | static void nxmq_add_queue(FAR struct mqueue_inode_s *msgq, |
链表是按优先级降序排列的。所以
prio=200的消息排在prio=100的前面,mq_receive()从链表头取消息即可获得最高优先级消息——O(1)取出,开销仅发生在mq_send时的 O(n) 插入。
3.5 消息接收:mq_receive() 完整链路
内核入口(文件:sched/mqueue/mq_receive.c:525-599):
与发送对称,mq_receive() 委托给 nxmq_receive() -> file_mq_receive():
1 | ssize_t nxmq_receive(mqd_t mqdes, FAR char *msg, size_t msglen, |
核心接收逻辑(文件:sched/mqueue/mq_receive.c:137-239,file_mq_timedreceive_internal):
1 | static ssize_t file_mq_timedreceive_internal(FAR struct file *mq, |
发送与接收的对称性:
| 阻塞条件 | 阻塞队列 | 任务状态 | 对端唤醒函数 | |
|---|---|---|---|---|
| 发送方 | nmsgs >= maxmsgs |
waitfornotfull |
TSTATE_WAIT_MQNOTFULL |
nxmq_notify_receive |
| 接收方 | nmsgs == 0 |
waitfornotempty |
TSTATE_WAIT_MQNOTEMPTY |
nxmq_notify_send |
这是经典的生产者-消费者同步模式:生产者满则等,消费者取走唤醒之;消费者空则等,生产者放入唤醒之。
3.6 阻塞与唤醒机制详解
消息队列的阻塞不是简单的 sleep()——它涉及调度器、优先级排序、while 循环重试和超时看门狗的四方协作。
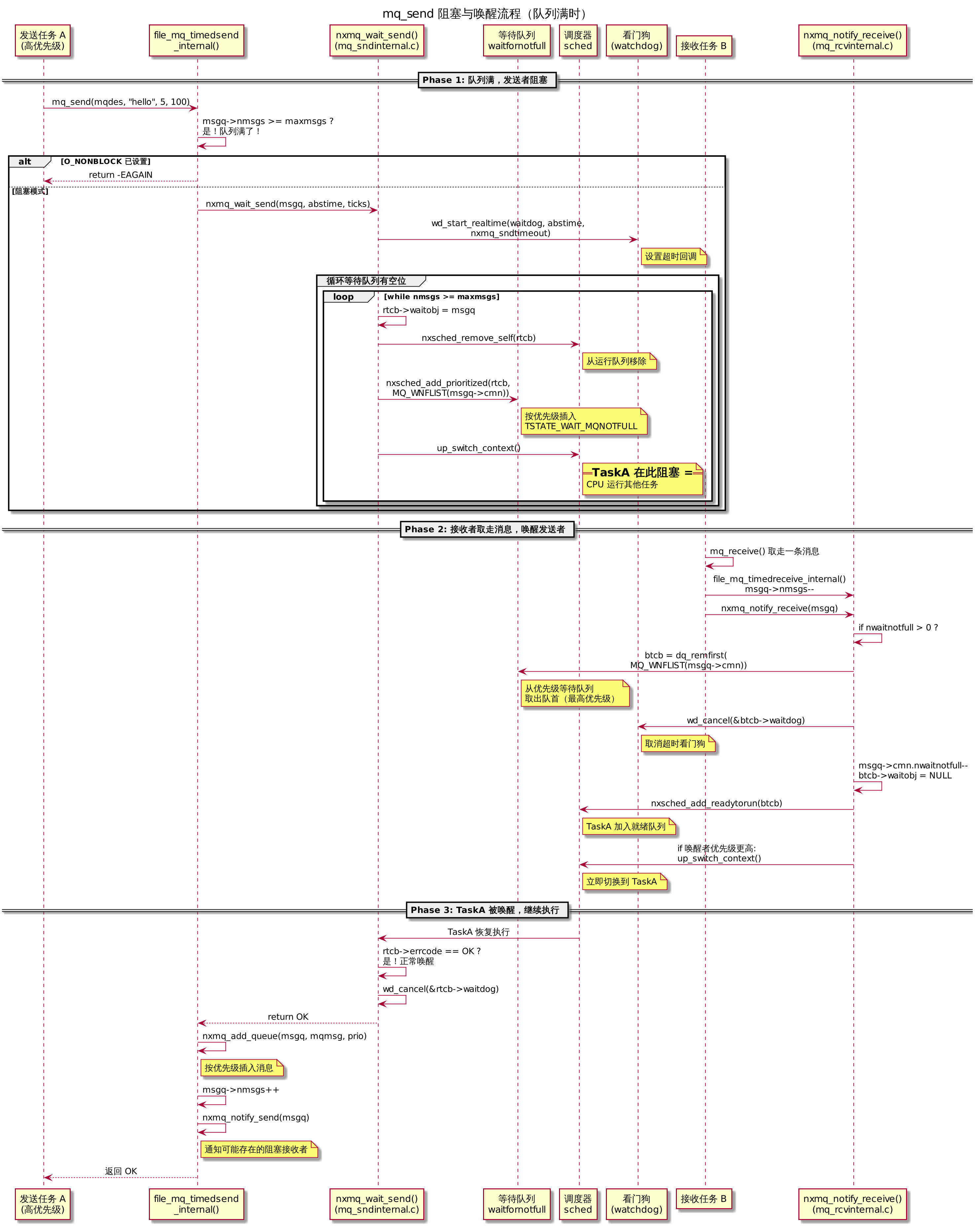
3.6.1 发送者阻塞(nxmq_wait_send)
文件:sched/mqueue/mq_sndinternal.c:127-218
1 | int nxmq_wait_send(FAR struct mqueue_inode_s *msgq, |
关键细节:
nxsched_add_prioritized()将 TCB 按优先级插入waitfornotfull链表——高优先级任务排前面,唤醒时先被取出。这与管道的 FIFO 唤醒不同。while循环绝对不能省:另一个更高优先级的等待者可能在当前任务重新运行前抢走了槽位,导致队列再次满了。rtcb->waitobj = msgq将当前任务与队列绑定——当任务被mq_close意外结束或信号杀死时,内核可通过waitobj将其从等待链表中移除。
下图展示了发送者阻塞与唤醒的完整时序——从 mq_send 发现队列已满开始,经调度器阻塞、接收者取走消息、notify 唤醒、到最后消息入队的全过程:
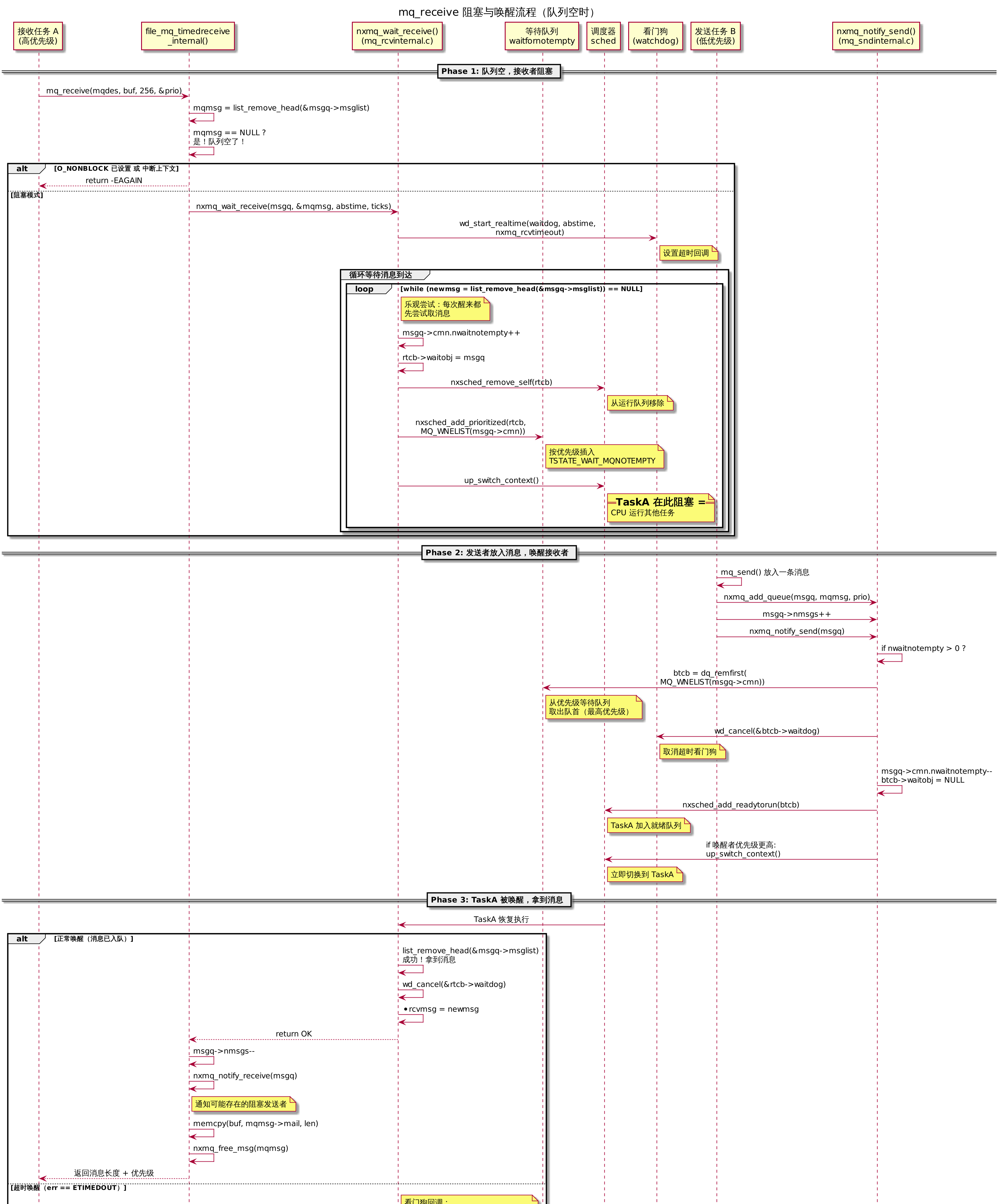
3.6.2 接收者阻塞(nxmq_wait_receive)
文件:sched/mqueue/mq_rcvinternal.c:127-207
1 | int nxmq_wait_receive(FAR struct mqueue_inode_s *msgq, |
注意:与
nxmq_wait_send不同,接收者 while 循环的内部也在尝试list_remove_head()——消息可能恰好在进入循环的瞬间被放入队列,此时直接拿到消息返回,根本不会阻塞。这是无锁编程中的”乐观尝试”模式。
下图展示了接收者阻塞与唤醒的完整时序——从 mq_receive 发现队列为空开始,经调度器阻塞、发送者放入消息、notify 唤醒,到最终拿到消息的全过程:
3.6.3 唤醒阻塞者(nxmq_notify_send / nxmq_notify_receive)
发送者放入消息后 → 唤醒接收者(mq_sndinternal.c:239-305):
1 | void nxmq_notify_send(FAR struct mqueue_inode_s *msgq) |
接收者取走消息后 → 唤醒发送者(mq_rcvinternal.c:231-272):
1 | void nxmq_notify_receive(FAR struct mqueue_inode_s *msgq) |
两个 notify 函数的对称性:
| 触发操作 | 调用函数 | 扫描的队列 | 被唤醒的任务状态 | 唤醒后的效果 |
|---|---|---|---|---|
mq_send 放入消息 |
nxmq_notify_send |
waitfornotempty |
TSTATE_WAIT_MQNOTEMPTY |
接收者 while 循环重试,拿到消息 |
mq_receive 取走消息 |
nxmq_notify_receive |
waitfornotfull |
TSTATE_WAIT_MQNOTFULL |
发送者 while 循环重试,队列有空位 |
3.6.4 超时机制
阻塞等待支持两种超时方式:
- 绝对时间(
mq_timedsend/mq_timedreceive):通过wd_start_realtime()设置截止时间。 - 相对 tick(内部接口):通过
wd_start()设置 tick 数。
超时回调函数(mq_sndinternal.c:68-93):
1 | static void nxmq_sndtimeout(wdparm_t arg) |
nxmq_wait_irq() 将任务的 errcode 设为 ETIMEDOUT,从等待队列中移除,再加入就绪队列。任务被调度执行时,while 循环检查 errcode != OK,跳出循环并返回错误。注意回调中重新检查 task_state——任务可能已在超时触发的瞬间被正常唤醒。
3.7 VFS 集成
消息队列在 VFS 中以 inode 形式存在,路径形如 /var/mqueue/myqueue,类型为 FSNODEFLAG_TYPE_MQUEUE。关联的文件操作表(fs/mqueue/mq_open.c:58-69):
1 | static const struct file_operations g_nxmq_fileops = { |
注意 read 和 write 操作为 NULL——消息队列必须通过 mq_send() / mq_receive() 专用 API 操作,不能用 read() / write() 系统调用。VFS 集成的真正意义是:支持 poll() 的统一事件通知(POLLIN / POLLOUT)、引用计数管理(close / unlink),以及与其他文件系统类型统一的路径管理。
3.8 对比:消息队列 vs 信号量 vs 管道阻塞机制
| 特性 | 消息队列 | 信号量 | 管道 |
|---|---|---|---|
| 阻塞队列类型 | 按优先级排序的 dq_queue_t |
按优先级排序的 dq_queue_t |
计数信号量 sem_t |
| 阻塞状态 | TSTATE_WAIT_MQNOTEMPTY/FULL |
TSTATE_WAIT_SEM |
信号量内部状态 |
| 唤醒顺序 | 按优先级(高优先级先醒) | 按优先级 | FIFO(先等先醒) |
| 超时支持 | 是(watchdog timer) | 是(watchdog timer) | 是(信号量超时) |
消息队列和信号量的阻塞机制都属于”调度器级优先级等待队列”——阻塞时将 TCB 按优先级插入到 dq_queue_t 中,唤醒时 dq_remfirst() 取出最高优先级者。这保证了实时系统中紧急任务能优先获得消息。
消息队列解决了”结构化消息传递”的问题。如果需要更高性能的大数据共享(避免拷贝),则需要共享内存。
4. 深入:共享内存内核实现(KERNEL 模式)
其他 IPC 都需要数据拷贝(用户→内核→用户,至少两次)。共享内存通过将同一物理页映射到多个进程的虚拟地址空间,实现零拷贝——进程 A 写入的数据,进程 B 立即可见,无需内核介入。
代价是:需要额外的同步机制(信号量/互斥锁)来协调读写时序。
下图展示了两个进程通过共享内存共享同一物理页的完整流程:
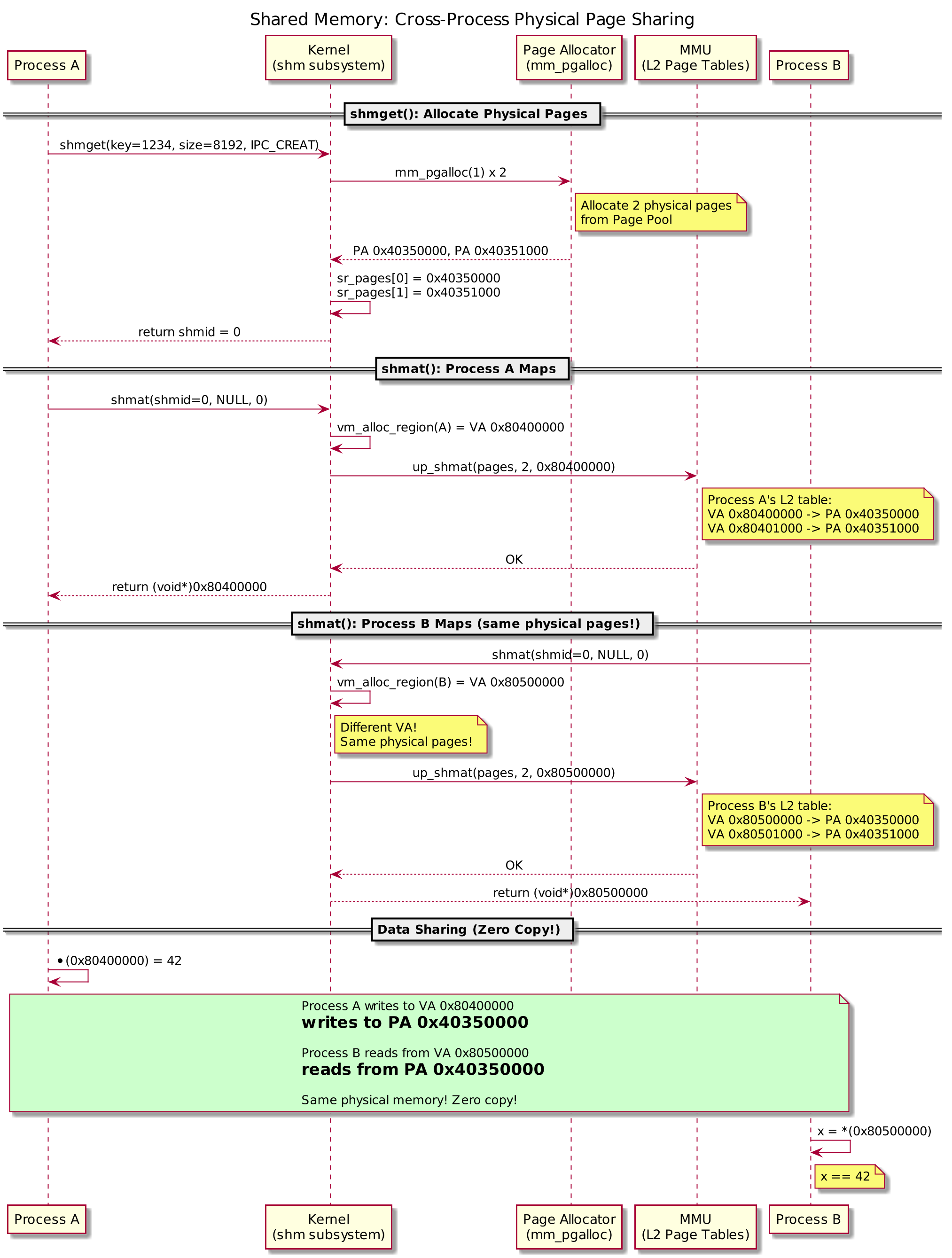
4.1 核心数据结构
文件:mm/shm/shm.h:83-93
1 | struct shm_region_s |
全局区域表:
1 | struct shm_info_s |
关键字段 sr_pages[]:存储该共享内存区域所有物理页的地址。多个进程通过各自的页表映射到这些相同的物理页——这就是”共享”的本质。
4.2 shmget():创建/获取共享内存
文件:mm/shm/shmget.c:364-482
1 | int shmget(key_t key, size_t size, int shmflg) |
4.3 shmat():映射到进程地址空间
文件:mm/shm/shmat.c:208-308
1 | FAR void *shmat(int shmid, FAR const void *shmaddr, int shmflg) |
4.4 up_shmat():ARMv7-A MMU 页表操作
文件:arch/arm/src/armv7-a/arm_addrenv_shm.c:69-156
这是共享内存的硬件层核心——将物理页写入调用进程的 L2 页表:
1 | int up_shmat(FAR uintptr_t *pages, unsigned int npages, uintptr_t vaddr) |
跨进程共享的本质:
1 | Process A L2 page table: Process B L2 page table: |
虚拟地址可以不同(每个进程的 VA 由 vm_alloc_region() 独立分配),但物理页相同——这就是零拷贝共享的原理。
虚拟地址可以不同(每个进程的 VA 由 vm_alloc_region() 独立分配),但物理页相同——这就是零拷贝共享的原理。
4.5 shmdt():解除映射
文件:mm/shm/shmdt.c:67-113
1 | int shmdt(FAR const void *shmaddr) |
注意:up_shmdt() 清除 PTE 但不释放物理页——物理页由 shm_destroy() 在最后一个 detach 且标记删除后统一释放。这确保了其他进程的映射不会失效。
4.6 POSIX shm_open 风格(通过 VFS)
除了 System V shmget/shmat,NuttX 也支持 POSIX shm_open() + mmap() 风格。它在 VFS 中以 /dev/shm/name 路径注册 inode,通过 shmfs 文件系统(fs/shm/shmfs.c)提供 read/write/mmap/truncate 操作。mmap() 内部调用相同的 MMU 映射逻辑。
共享内存实现了零拷贝高性能共享。如果只需简单的流式字节传输,管道是更轻量的选择。
5. 深入:管道内核实现
管道是最简单的 IPC——一端写入字节流,另一端读取。没有消息边界、没有优先级、没有MMU操作。核心就是一个环形缓冲区 + 两个信号量。开销极低,适合大量小数据的顺序传递(如 shell 管道 ls | grep)。
5.1 核心数据结构
文件:drivers/pipes/pipe_common.h:118-140
1 | struct pipe_dev_s |
文件:include/nuttx/circbuf.h:52-59
1 | struct circbuf_s |
环形缓冲区的可用空间 = size - (head - tail) - 1(保留 1 字节区分满/空)。
5.2 pipe() 创建流程
文件:drivers/pipes/pipe.c:258-311
1 | int pipe2(int pipefd[2], int flags) |
FIFO 的区别:mkfifo() 注册的设备节点不会被注销——它持久存在于 VFS 中,任何进程都可以通过路径名打开。
5.3 写入:pipecommon_write()
文件:drivers/pipes/pipe_common.c:506-656(关键逻辑摘录)
1 | static ssize_t pipecommon_write(FAR struct file *filep, |
5.4 读取:pipecommon_read()
文件:drivers/pipes/pipe_common.c:415-500(关键逻辑摘录)
1 | static ssize_t pipecommon_read(FAR struct file *filep, |
5.5 阻塞机制
管道使用两个计数信号量(不是按优先级排序的等待队列):
| 信号量 | 阻塞条件 | 唤醒时机 |
|---|---|---|
d_rdsem |
缓冲区空,读者等待 | 写者写入数据后 post |
d_wrsem |
缓冲区满,写者等待 | 读者取走数据后 post |
与消息队列阻塞的区别:消息队列用调度器级别的优先级等待队列(高优先级任务先被唤醒),管道用简单的计数信号量(FIFO 唤醒顺序)。
5.6 关闭语义
- 最后一个写端关闭:读者收到 EOF(
read()返回 0)+ POLLHUP - 最后一个读端关闭:写者收到
-EPIPE+ POLLERR + 可能收到 SIGPIPE
6. 选择指南:何时用哪种 IPC
| 场景 | 推荐 IPC | 理由 |
|---|---|---|
| 保护临界区 | mutex / semaphore | 最低开销,无数据传输 |
| 小消息传递(< 1KB) | mqueue | 带优先级、带边界、阻塞语义完善 |
| 大数据共享(缓冲区/帧) | shared memory + mutex | 零拷贝,性能最高 |
| 流式字节传输 | pipe / FIFO | 简单、符合 Unix 哲学 |
| 跨进程通知(无数据) | signal | 异步、不需要接收方主动等待 |
| 生产者/消费者队列 | mqueue 或 pipe | mqueue 有优先级;pipe 更简单 |
7. 对比分析
| 特性 | Semaphore | Mqueue | Shared Memory | Pipe |
|---|---|---|---|---|
| 数据传输 | 无 | 有(结构化消息) | 有(任意内存) | 有(字节流) |
| 拷贝次数 | 0 | 2(用户→内核→用户) | 0(零拷贝) | 2(用户→内核→用户) |
| 优先级排序 | — | 有(消息按 prio 排) | — | — |
| 消息边界 | — | 有 | — | 无 |
| 跨进程可用 | 命名信号量可 | 是 | 是(仅 KERNEL 模式) | FIFO 可 |
| VFS 集成 | /sem/name |
/var/mqueue/name |
/dev/shm/name |
/dev/pipe/N |
| 阻塞机制 | 调度器优先级队列 | 调度器优先级队列 | 无(需用户同步) | 计数信号量 |
| KERNEL 模式要求 | 无 | 无 | 必须 | 无 |
8. 关键要点
消息队列按优先级排序——
mq_send()将消息插入到有序链表中正确位置,mq_receive()总是取出链表头(最高优先级)。共享内存是唯一的零拷贝 IPC——通过将同一物理页映射到多个进程的 L2 页表实现,仅在 KERNEL 模式(有 MMU)下可用。
管道用环形缓冲区 + 两个信号量实现读写阻塞——缓冲区空时读者在
d_rdsem等待,满时写者在d_wrsem等待。消息队列的阻塞使用调度器级优先级等待队列(
TSTATE_WAIT_MQNOTEMPTY/FULL),高优先级任务优先被唤醒;管道用简单信号量(FIFO 顺序)。共享内存的
shmat()不分配物理页——物理页在shmget()时已分配。shmat()只是将已有物理页映射到调用进程的页表中。匿名管道在
pipe()后立即从 VFS 注销路径——只有持有 fd 的进程能访问,体现了”匿名”语义。FIFO 的路径持久存在。KERNEL 模式下所有 IPC 调用都走 SVC 系统调用路径——
sys_call4宏触发svc指令,arm_syscall()→dispatch_syscall()→g_stublookup[]→ STUB → 内核实现,形成完整的用户态到内核态的桥接。所有 IPC 的阻塞等待都支持超时——
mq_timedreceive()、sem_timedwait()通过 watchdog timer 实现。
9. 参考文件索引
| 文件路径 | 关键内容 | 引用行号 |
|---|---|---|
include/nuttx/mqueue.h |
mqueue_inode_s, mqueue_cmn_s | 103-131 |
sched/mqueue/mqueue.h |
mqueue_msg_s, 全局消息池 | 68-105 |
sched/mqueue/mq_send.c |
mq_send(), nxmq_add_queue() | 206-369 |
sched/mqueue/mq_receive.c |
mq_receive(), file_mq_timedreceive_internal() | 137-239 |
sched/mqueue/mq_sndinternal.c |
nxmq_wait_send(), nxmq_notify_send() | 127-306 |
sched/mqueue/mq_rcvinternal.c |
nxmq_wait_receive(), nxmq_notify_receive() | 127-273 |
fs/mqueue/mq_open.c |
mq_open() VFS 集成, file_mq_vopen() | 160-520 |
arch/arm/include/syscall.h |
sys_call4 宏(SVC 内联汇编) | 306-323 |
arch/arm/src/armv7-a/arm_syscall.c |
arm_syscall(), dispatch_syscall() | 123-556 |
syscall/syscall_stublookup.c |
g_stublookup[] 存根表 | 88-95 |
syscall/syscall.csv |
系统调用签名定义(mksyscall 输入) | 74-76 |
mm/shm/shm.h |
shm_region_s, shm_info_s | 83-103 |
mm/shm/shmget.c |
shmget(), shm_extend(), g_shminfo | 47-482 |
mm/shm/shmat.c |
shmat(), munmap_shm() | 208-308 |
mm/shm/shmdt.c |
shmdt() | 67-113 |
mm/shm/shmctl.c |
shmctl(), shm_destroy() | 108-248 |
arch/arm/src/armv7-a/arm_addrenv_shm.c |
up_shmat(), up_shmdt() (MMU 操作) | 69-242 |
fs/shm/shmfs.c |
shmfs 文件操作(read/write/mmap) | 65-368 |
drivers/pipes/pipe_common.h |
pipe_dev_s, circbuf_s | 118-140 |
drivers/pipes/pipe_common.c |
pipecommon_read/write/open/close | 134-952 |
drivers/pipes/pipe.c |
pipe2(), pipe_register() | 60-311 |
drivers/pipes/fifo.c |
nx_mkfifo() | 100-120 |
include/nuttx/circbuf.h |
circbuf_s, circbuf_read/write | 52-320 |
外部参考文档:
| 文档 | 说明 |
|---|---|
| IEEE Std 1003.1 (POSIX.1-2017) | mqueue, shm, semaphore, pipe 标准接口定义 |
| NuttX Documentation: https://nuttx.apache.org/docs/latest/ | 官方 API 参考和配置指南 |
| ARM Architecture Reference Manual (ARMv7-A/R) | L2 页表映射(共享内存 MMU 操作) |