嵌入式设备经常会遇到各种各样的异常,理解和掌握如何快速调试和解决这类问题非常重要。
本文主要介绍如何在ARM Cortex-M设备上调试异常,包括错误寄存器和如何自动进行故障分析。
Cortex-M 系列的MCU有几种不同的状态,发生故障时我们可以分析这些状态,以追查问题发生的原因。
1 错误状态寄存器
1.1 Configurable Fault Status Registers(CFSR)- 0xE000ED28
这个32位寄存器包含发生并导致异常的故障的主要信息。它包含了三个不同的状态寄存器:UFSR、BFSR和MMFSR

可以通过0xE000ED28处的32位读取访问该寄存器,也可以单独读取每个寄存器。
- 整个CFSR -
print/x *(uint32_t *) 0xE000ED28 - UFSR -
print/x *(uint16_t *) 0xE000ED2A - BFSR -
print/x *(uint8_t *) 0xE000ED29 - MMFSR -
print/x *(uint8_t *) 0xE000ED28
1.1.1 Usage Fault Status Register (UFSR) - 0xE000ED2A
这个寄存器由2字节,它总结了与内存访问失败无关的任何故障,如执行了无效指令、尝试进入无效状态。
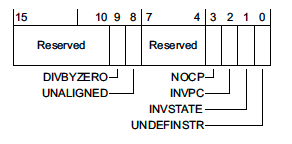
其中,
DIVBYZERO - 除零错误。该故障是可配置的。
UNALIGNED - 表示发生了未对齐的访问操作。未对齐的多字访问,例如访问非 8 字节对齐的 uint64_t,将产生此错误。除 Cortex-M0 MCU 外,4 字节以下的未对齐访问是否产生故障也是可配置的。
NOCP - 指示已发出 Cortex-M 协处理器指令,但协处理器已禁用或不存在。发生此故障的一种常见情况是,当代码被编译为使用浮点扩展 (
-mfloat-abi=hard -mfpu=fpv4-sp-d16) 但协处理器未在启动时启用。INVPC - 指示 EXC_RETURN 上的完整性检查失败。如果设置了此故障标志,则意味着在异常退出时使用了保留的 EXC_RETURN 值。
INVSTATE - 表示处理器尝试执行某个指令,但程序状态寄存器 (EPSR) 的值是无效的。
一般情况下,ESPR 指示处理器是否处于 Thumb 模式。使用
bx & blx 或 ldr & ldm加载 pc 相对值时,必须将指令的位 [0] 设置为 1。如果违反此规则,将生成一个 INVSTATE 异常。一般编写 C 代码时,编译器会自动处理此问题。但如果是手写汇编的话,就比较可能出现这个错误。平时在实践中,最常见的是传入一个错误的PC值(如注册的callback是非法的),然后进行跳转,就容易出现这个错误。
UNDEFINSTR - 表示执行了未定义的指令。如果堆栈损坏,这可能会在异常退出时发生。编译器也可能会针对应该无法访问的代码路径发出未定义的指令。
Configurable UsageFault
某些usage fault的类型可以通过CCR寄存器来配置是否使能。
- Bit 4 (DIV_0_TRP) - 控制除0是否产生错误
- Bit3 (UNALIGN_TRP) - 控制非对齐访问是否产生错误
1.1.2 BusFault Status Register (BFSR) - 0xE000ED29
这是一个1字节的寄存器,用来汇总与指令预取和内存访问失败相关的故障。
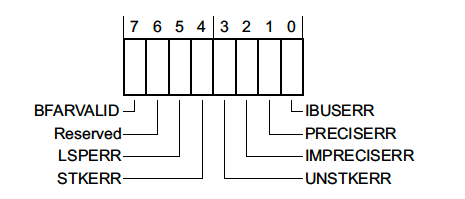
- BFARVALID - 表示总线故障地址寄存器 (BFAR-0xE000ED38) 是否保存了触发故障的地址。
- LSPERR & STKERR - 分别表示在惰性状态保存期间(lazy state preservation)或异常进入期间发生的故障。这两种情况都是硬件自动在堆栈上保存状态。可能发生此错误的一种方式是,在尝试处理异常时栈溢出了有效的 RAM 地址范围。
- UNSTKERR - 表示尝试从异常返回时发生错误。通常发生这种错误的情况是:在处理异常时堆栈破坏,或者切换栈帧时栈里面的内容没有正确地初始化。
- IMPRECISERR - 这个标志非常重要。它告诉我们硬件是否能够确定故障的确切位置。这种错误一般比较难查一点。
- PRECISERR - 表示在异常进入之前正在执行的指令触发了错误。这种情况下异常发生时自动保存的PC就是导致错误的PC。
非精确错误的调试建议
非精确错误是最难查的错误,这意味着堆栈在异常入口处的寄存器不会指向导致异常的代码。
Cortex-M设备上,指令预取和数据加载通常产生的是同步的错误,并且是精确的。而存储操作则会发生异步故障。这是因为写入操作有时候会被缓存,所以有时候PC会在数据存储完成之前增加。
当遇到一个不精确的错误时,我们需要检查报告异常区域看起来可疑的存储指令。如果MCU支持ARM Embbedded Trace Macrocell(ETM),一些调试器可以查看最近执行指令的历史纪录。
1.1.3 Auxiliary Control Register (ACTLR) - 0xE000E008
辅助控制寄存器。这个寄存器关闭一些硬件优化或特性(通常会带来性能的损失和中断的延迟)。
对Cortex M3和M4,可以通过设置这个寄存器的 bit 1(DISDEFWBUF) 为1,来关闭写缓冲,从而让所有的非精确错误都变成精确错误。
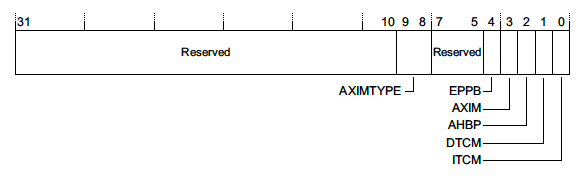
1.1.4 Auxiliary Bus Fault Status Register (ABFSR) - 0xE000EFA8
这个寄存器仅存在于Cortex-M7设备。当非精确错误发生时,这个寄存器可以指示错误发生在什么内存总线上。
1.1.5 MemManage Status Register (MMFSR) - 0xE000ED28
这个寄存器报告了MPU相关的错误。
一般来说只有MPU被配置并使能之后才会产生MPU错误。但是有一些内存访问错误也会出发MemManage Fault。如:尝试在系统地址范围(0xExxx.xxxx)内执行代码。
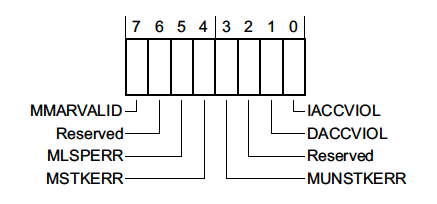
- MMARVALID - 表示 MemManage 故障地址寄存器 (MMFAR - 0xE000ED34) 中是否保存了触发 MemManage 故障的地址。
- MLSPERR & MSTKERR - 分别表示在惰性状态保存或异常进入期间发生了 MemManage 故障。例如,如果使用 MPU 区域检测堆栈溢出,就有可能会发生这种情况。
- MUNSTKERR - 表示从异常返回时发生错误
- DACCVIOL - 表示数据访问触发了 MemManage 故障。
- IACCVIOL - 指示尝试执行一条指令触发了 MPU 或从不执行 (XN) 故障。
1.2 HardFault Status Register (HFSR) - 0xE000ED2C
这个寄存器表示发生了 HardFault。
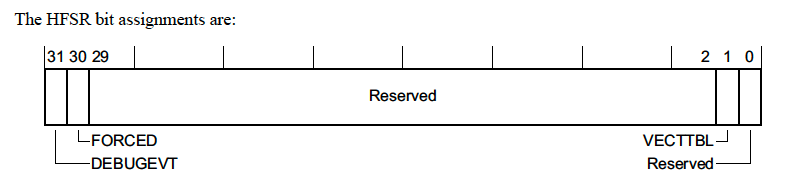
- DEBUGEVT - 未启用调试子系统时发生了指示调试事件(即执行断点指令)
- FORCED - 这意味着可配置故障(即我们在前面部分讨论的故障类型)升级为 HardFault,如可配置故障处理程序未启用,或者在handler中发生了故障。
- VECTTBL - 表示由于从向量表中的地址读取问题而发生故障。这种情况很少,但如果向量表中存在错误地址并且意外中断触发,则可能会发生这种情况。
2 调用栈恢复
如果可以复现问题,我们可以在异常处理函数处添加断点:
1 | (gdb)break HardFault_Handler |
在异常发生时,一些寄存器会自动压栈。(FPU开启会压更多的寄存器)
Cortex-M设备有两个栈指针,msp和psp。在异常发生时,EXC_RETURN 会被保存在 lr 寄存器中,它的bit 2指示了发生异常时使用的是msp还是psp。如果bit2为1,则使用psp,否则使用msp。
示例:
1 | int illegal_instruction_execution(void) { |
如果我们在异常入口添加了断点:
1 | (gdb) p/x $lr |
当我们知道sp之后,我们就可以从栈中恢复异常发生前的 callstack。
2.1 异常中再发生异常
如果在异常中再次发生异常,会发生什么?
如果使能了可配置错误寄存器(如MemManage, BusFault, UsageFault),这些异常处理程序中的错误,会升级为HardFault。
一旦到了HardFault,ARM Core就会在不可配置的优先级(-1)上执行。这时候,错误会使得处理器处于无法恢复的状态,需要重置。这种状态被成为锁定(Lockup)。
通常处理器会在进入锁定状态后自动复位,但这不是规范中要求的。这时候,你可以通过使能硬件看门狗来进行复位。
如果接上了调试器,lockup可能会有不同的行为。如在NRF52840上,处于调试模式时lockup是关闭的。
当发生lockup时,处理器会重复执行相同的指令,0xFFFFFFFE,或者出发lockup的指令,直到复位。
3 自动错误分析
现在我们已经掌握了错误分析的主要信息。接下来我们看如何自动分析这些错误。
3.1 暂停和确定核心寄存器状态
第一步,我们在系统异常的时候触发一个断点:
1 | // NOTE: If you are using CMSIS, the registers can also be |
为了不需要手动展开寄存器状态,我们定义一个c的结构体:
1 | typedef struct __attribute__((packed)) ContextStateFrame { |
我们可以通过一段小的汇编指令来确定在错误发生时使用的是msp还是psp,并把sp传给my_fault_handler_c:
1 |
|
这时候,我们的c的处理函数可以写成这个样子:
1 | // 关闭优化,以确保frame参数不会被优化掉 |
如果接着调试器,我们就可以把寄存器状态打印出来:
1 | 0x00000244 in my_fault_handler_c (frame=0x200005d8 <ucHeap+1136>) at ./cortex-m-fault-debug/startup.c:94 |
这时候,我们就有了一个错误的现场,我们可以结合PC,LR,SP,来做进一步的分析,内存变量也都可以查看。
3.2 调试插件
很多IDE都有插件可以看到寄存器。这些实现通常是利用了CMSIS系统视图描述格式文件(System View Description),它是一个XML的标准格式,用来描述ARM MCY的内存映射寄存器。
你甚至可以通过GDB来加载这些文件,如 PyCortexMDebug,一个GDB的python脚本。
这是一个实例:
1 | (gdb) source cmdebug/svd_gdb.py |
3.3 事后分析(Postmortem Analysis)
通常说的保存dump文件,就是事后分析。我们可以参考CmBacktrace之类的一些开源组件来完成。它里面的代码,就是对上述知识点的运用。
参考资料: